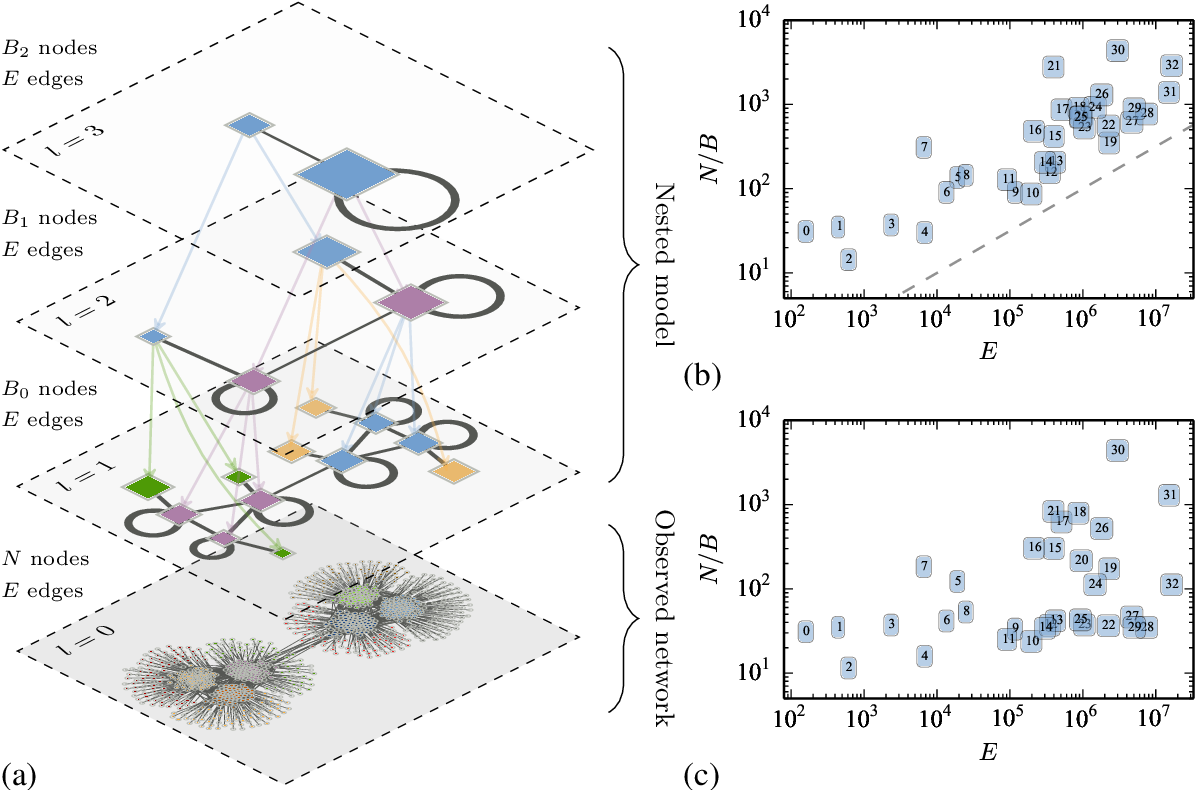
What is Community? 🐦
- “Birds of a feather flock together”
- In networks, communities are groups of nodes with similar connection patterns.
- They can reflect:
- Homophily: similar nodes connect.
- Functional groups: nodes collaborating for a purpose.
- Hierarchical structure: communities within communities.

Pattern Matching 🧩: Cliques
- Clique: a group of nodes where everyone is connected to everyone else.
- The strictest definition of a community.
- Often too rigid for real-world networks.
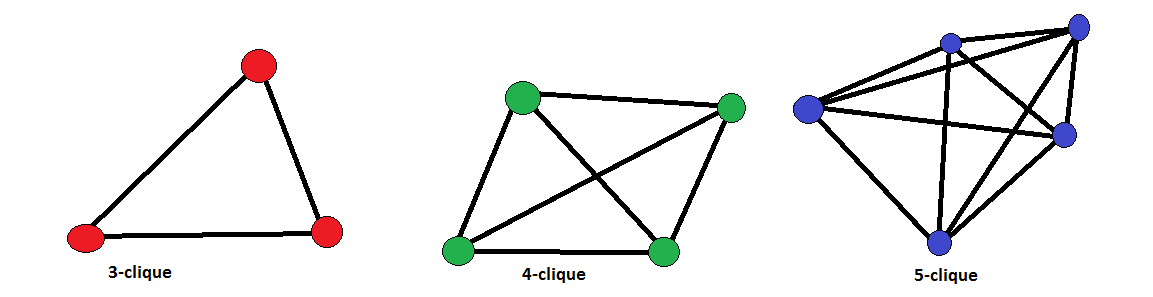
Image of cliques
Clique Percolation (Palla 2005 Nature)
- Idea: Communities are formed by overlapping cliques
- Start with all k-cliques in the network
- Two k-cliques are connected if they share k-1 nodes
- Communities are connected components in this “clique graph”

Advantages:
Allows overlapping communities, based on strong local cohesion, and parameter \(k\) controls the number of communities.
Issue of cliques
Real-world groups are rarely perfect cliques. We relax the definition along three dimensions:
- Degree: Not every node needs to be fully connected.
- Density: The group doesn’t need all possible edges.
- Distance: Members can be a few steps away from each other.
Hybrid Approaches
Combine dimensions to capture tightly-knit community structures.
- k-truss: every edge must be part of at least \(k-2\) triangles. Emphasizes triadic closure.
- \(\rho\)-dense core: balances high internal density with sparse external connections.

Overview: Optimization Approach
- Define a quality function for a partition of nodes into communities.
- Search for the partition that maximizes (or minimizes) this function.
- Examples:
- Graph Cut
- Balanced Cut
- Modularity

Graph Cut 🔪
Goal: Minimize the number of edges needed to cut to separate the graph into communities. \[ \text{argmin}_{V_1, V_2} \text{Cut}(V_1, V_2) = \sum_{i \in V_1} \sum_{j \in V_2} A_{ij}, \]
where \(V_1\) and \(V_2\) are the disjoint sets of nodes (i.e., \(V_1 \cap V_2 = \emptyset\) and \(V_1 \cup V_2 = V\)), and \(A_{ij}\) is the adjacency matrix.
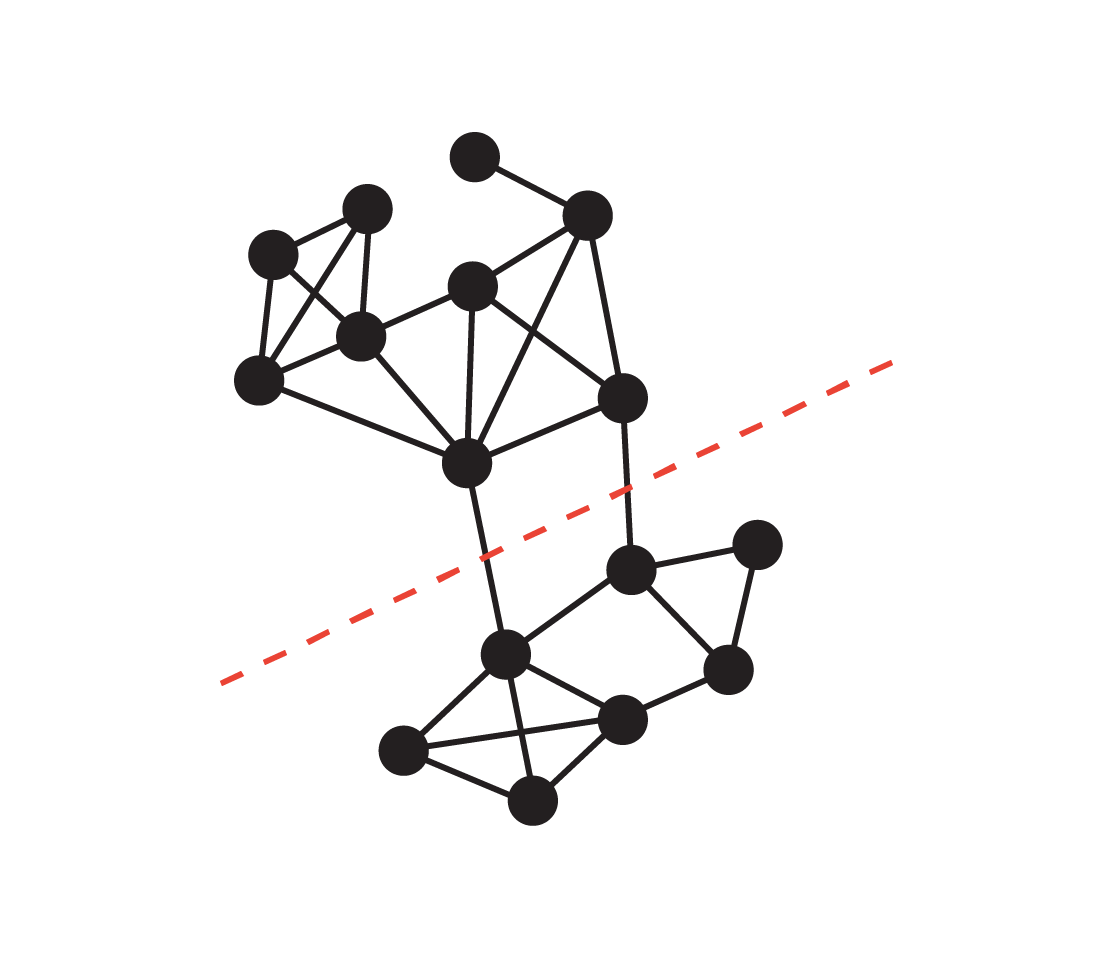
This problem statement is incomplete 🫣. Find out what’s missing by playing with the following game. Graph Cut Problem 🎮
The Ball and String Game 🎨🧵
Imagine colored balls (nodes) and strings (edges).
- Count how many strings connect balls of the same color.
- Cut all strings, throw the ends in a bag, and draw them randomly.
- Modularity = (1) - (2)
Modularity on Random Graphs
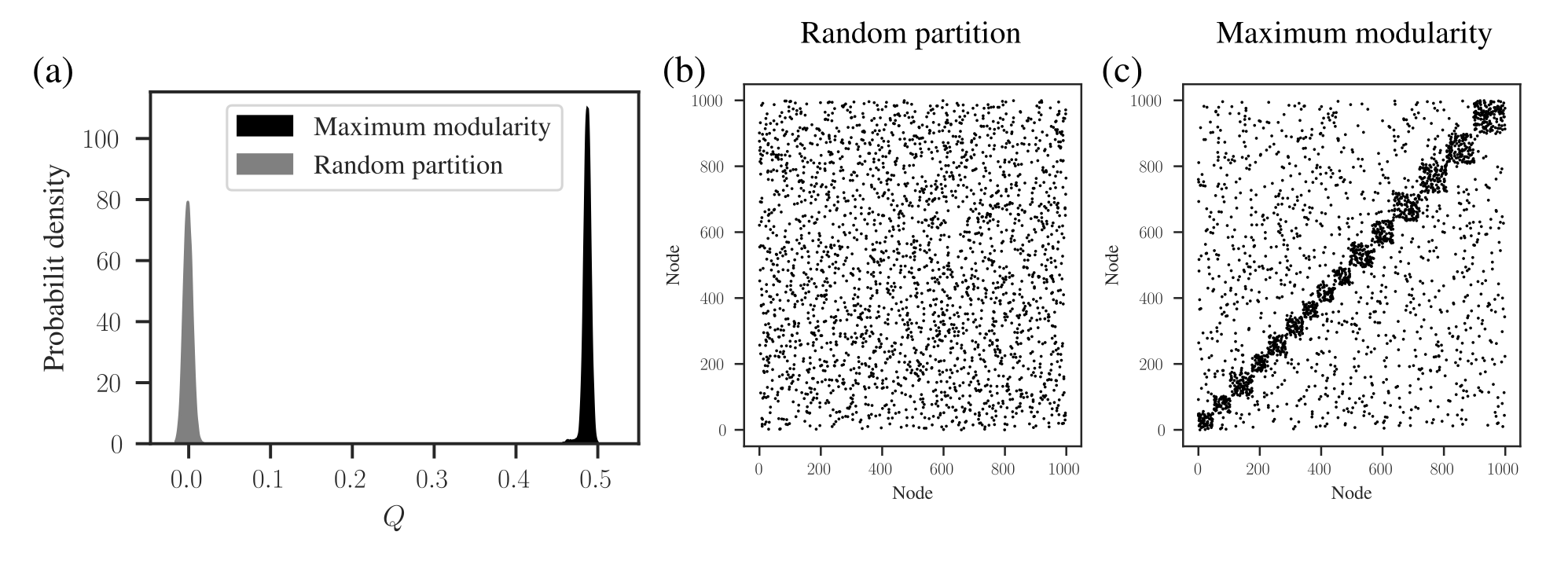
- A high modularity score doesn’t always mean we’ve found meaningful communities.
- Sparse networks tend to have higher modularity scores.
- We can’t compare modularity scores across different networks!
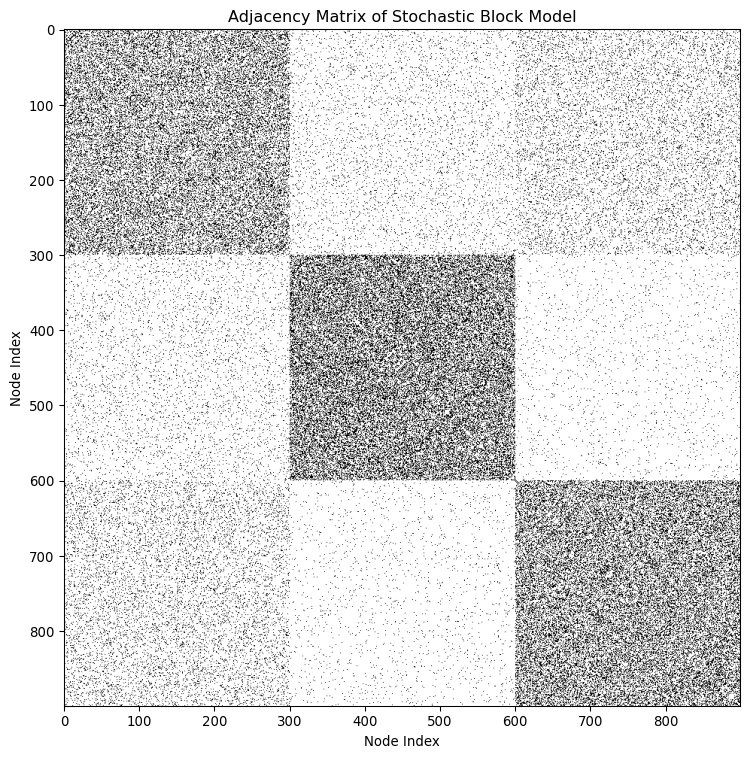
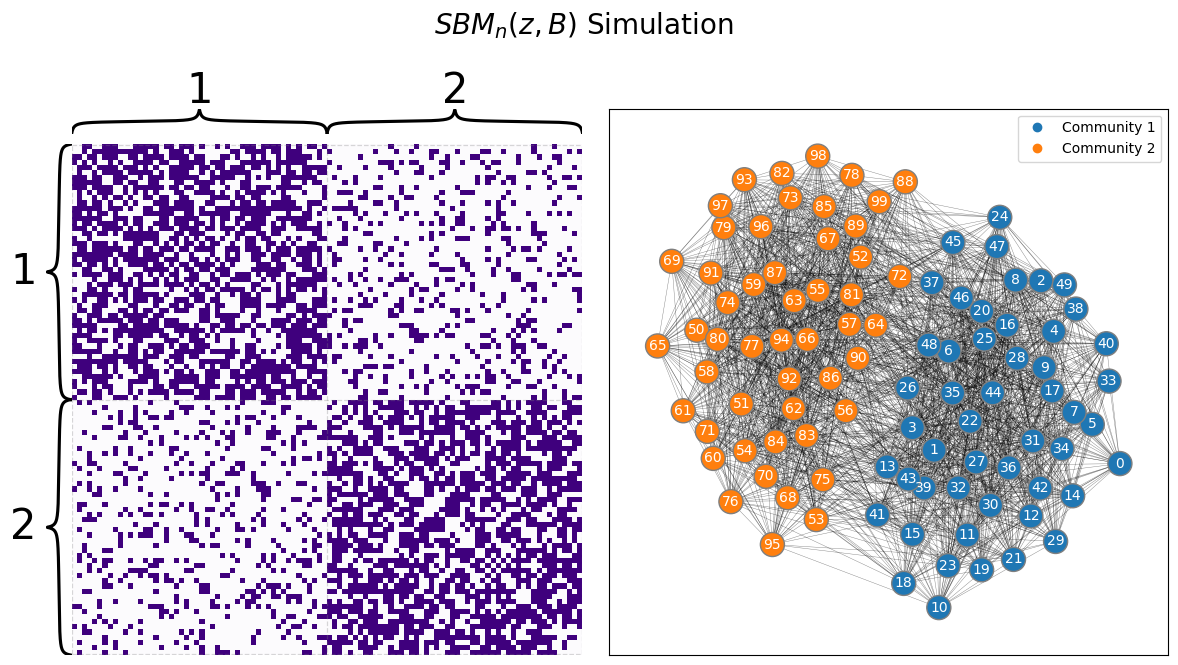
Stochastic Block Model (SBM)
Instead of defining what a community is, SBM defines how a network is generated from communities.
- It’s a generative model for networks with community structure.
- Nodes are assigned to blocks (communities).
- SBM specifies the probability \(p_{c_i, c_j}\) of an edge between two nodes in blocks \(c_i\) and \(c_j\) as:
\[ P(A_{ij} = 1 | c_i, c_j) = p_{c_i, c_j} \]
The SBM extends the notion of communities, i.e., a community is a group of nodes that connect to othe nodes in a similar way.
Allow for more broad definitions of communities.
- Assortative communities: Densely connected within and sparsely connected between.
- Disassortative communities: Sparsely connected within and densely connected between.
- Mixed communities: Core-periphery structure.

Given a network, we can infer the most plausible community structure that generated it (if it was generated by SBM) by maximizing the likelihood function, i.e.,
\[ \begin{aligned} &\text{argmax}_{c_1, \ldots, c_n, \theta} \sum_{i<j} \ell_{ij}(c_i, c_j, \theta), \\ &\ell_{ij} = A_{ij} \log p_{c_i, c_j} + (1 - A_{ij}) \log (1 - p_{c_i, c_j}), \end{aligned} \]
where \(c_i\) is the community of node \(i\), \(\theta\) is the parameters of the SBM, and \(p_{c_i, c_j}\) is the probability of an edge between two nodes in blocks \(c_i\) and \(c_j\).
SBM is a generative model for networks with community structure.
It can generate networks with community structure.
Extensions of SBM
SBM often produces homogeneous degree distributions when the number of communities is small, making it unsuitable for networks with heterogeneous degree distributions.
dcSBM addresses this limitation, and often yields more meaningful communities than the standard SBM.
Hierarchical SBM (hSBM): Models communities within communities, capturing nested structures. This SBM is free from the resolution limit problem!