Suppose that there is no horizontal line. You’ll win if you choose the line above the treasure.
Now, consider adding few horizontal lines. You’ll only move other lines few times, and you’ll end up with being on the line centered around the treasure with high probability.
The chance of winning “diffuses” as the number of horizontal lines increases, with limit close to uniform.
This is a network!
Random Walks in Networks 🌐
🚶♀️ Simple process: Start at a node, randomly move to neighbors
🏙️ Analogy: Drunk person walking in a city
Interestingly, this random process captures many important properties of networks
Unifies different concepts in network science, e.g., centrality, community structure
where \(A_{ij}\): Adjacency matrix element, and \(k_i\): Degree of node \(i\).
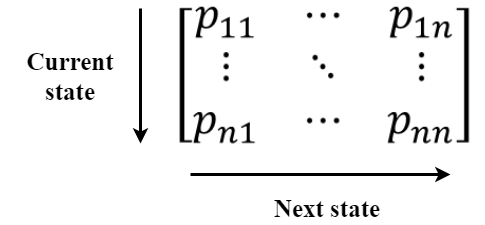
In matrix form
\[
\mathbf{P} = \mathbf{D}^{-1}\mathbf{A}
\]
where \(\mathbf{D}\): Diagonal matrix of node degrees.
Stationary Distribution 📈
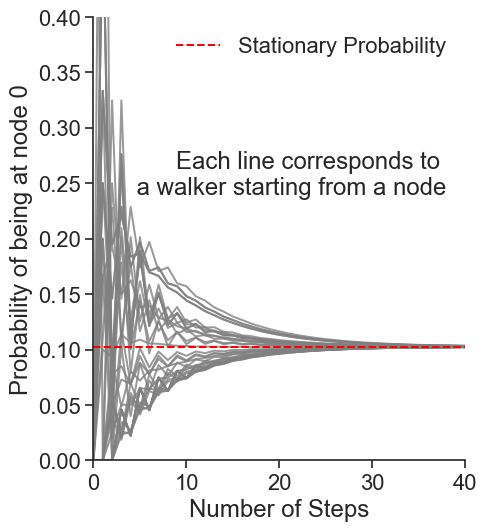
Let us consider a random walk on an undirected network starting from a node. After sufficiently many steps, where will the walker be?
Let \(x_i(t)\) be the probability that a random walker is at node \(i\) at time \(t\).
After many steps, \(\lim_{t\to\infty} x_i(t) = \pi_i\), which is time invariant, \(\pi_i\) is called the stationary distribution
At stationary state,
\[
{\bf \pi} = {\bf \pi P}
\]
What is the solution?
Stationary Distribution
This is the eigenvalue problem.
\[
{\bf \pi} = {\bf \pi P}
\]
One of the left-eigenvector of \({\bf P}\) is the stationary distribution
Question: - There are \(N\) left-eigenvectors for a network with \(N\) nodes. Which one represents the stationary distribution?
Coding Exercise:
Create a karate-club graph.
import igraph as igimport numpy as npg = ig.Graph.Famous("Zachary") # Load the Zachary's karate club networkA = g.get_adjacency_sparse() # Get the adjacency matrix
Task 1: Create a line plot of the probability distribution of the random walker over the nodes as a function of the number of steps. Create the plot for walkers starting from node 0, 32, or 6.
Task 2: Compute the stationary distribution using the eigenvector problem \({\bf \pi} = {\bf \pi P}\). You may want to use np.linalg.eig to compute the (left) eigenvectors and eigenvalues of the matrix \({\bf P}\).
Task 3: Compare the stationary distribution with the degree distribution.
Transient state
Transient State
Transient state captures the local structure around the starting node.
e.g., community structure, cycles, degree assortativity, etc.
Time to reach the stationary distribution within a certain tolerance \(\epsilon\).
Mixing Time
Random walk distribution \({\bf x}(t)\) at time \(t\) is given by
\[
{\bf x}(t) = {\bf x}(0) \mathbf{P}^t.
\]
where
\({\bf x}(0)\): Initial state vector
\({\bf x}(t)\): State vector at time \(t\)
The mixing time depends on the initial state \({\bf x}(0)\) and \({\bf P}^t\).
The network structure is encapsulated in \({\bf P}\). But this does not tell us what structure in \({\bf P}\) affects the mixing time. 🤔
What’s your expectation?
What network structure affects the mixing time, and in what way?
How does this structure show up in the transition probability matrix \({\bf P}\)?
\[
{\bf x}(t) = {\bf x}(0) \mathbf{P}^t.
\]
Let’s arm ourselves with some matrix algebra 🧰
Diagonalizability
Diagonalizable matrix: A matrix \(\mathbf{S}\) is diagonalizable if \({\bf S}\) can be represented as \(\mathbf{S} = \mathbf{Q}\mathbf{\Lambda}\mathbf{Q}^{-1}\), where \(\mathbf{Q}\) is an invertible matrix and \(\mathbf{\Lambda}\) is a diagonal matrix of eigenvalues.
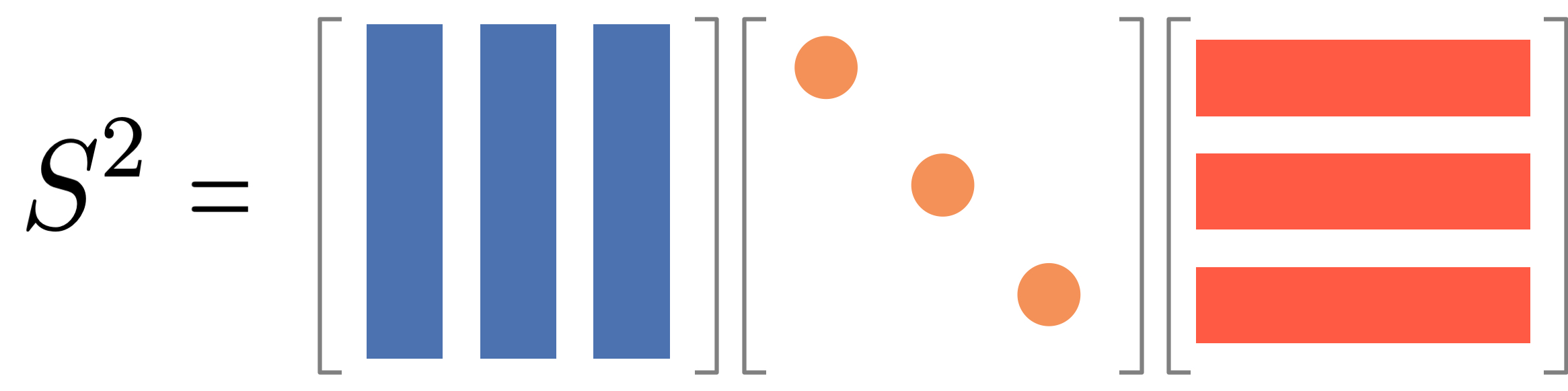
Exercise: Diagonalizabilty helps us to compute a power of a matrix easily. Compute the power \({\bf S}^2\) of diagonalizable matrix \({\bf S} = \mathbf{Q}\mathbf{\Lambda}\mathbf{Q}^{-1}\).
Task 1: Construct the adjacency matrices of two graphs as follows:
Task 2: Compute the normalized adjacency matrix \({\bf \overline A} = \mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}}\), where \(\mathbf{D}\) is the degree diagonal matrix.
Task 3: Compute the relaxation time \(\tau = \frac{1}{1-\lambda_2}\) using the second largest eigenvalue \(\lambda_2\) of the normalized adjacency matrix.
Relationship between Random Walks, Modularity, and Centrality 🌟