In this section, we implement the embedding methods discussed in the concepts section.
1 Data Preparation
We will use the karate club network throughout this notebook.
import numpy as npimport igraphimport matplotlib.pyplot as pltimport seaborn as sns# Load the karate club networkg = igraph.Graph.Famous("Zachary")A = g.get_adjacency_sparse()# Get community labels (Mr. Hi = 0, Officer = 1)labels = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])g.vs["label"] = labels# Visualize the networkpalette = sns.color_palette().as_hex()igraph.plot(g, vertex_color=[palette[label] for label in labels], bbox=(300, 300))
2 Spectral Embedding
Example: Spectral Embedding with Adjacency Matrix
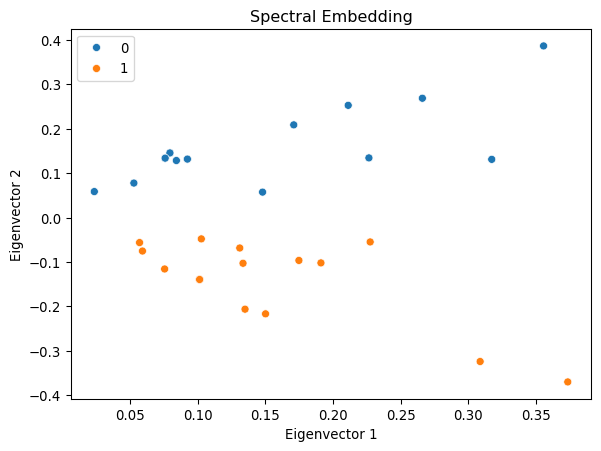
Let us demonstrate spectral embedding with the karate club network.
# Convert to dense array for eigendecompositionA_dense = A.toarray()
# Compute the spectral decompositioneigvals, eigvecs = np.linalg.eig(A_dense)# Find the top d eigenvectorsd =2sorted_indices = np.argsort(eigvals)[::-1][:d]eigvals = eigvals[sorted_indices]eigvecs = eigvecs[:, sorted_indices]# Plot the resultsfig, ax = plt.subplots(figsize=(7, 5))sns.scatterplot(x = eigvecs[:, 0], y = eigvecs[:, 1], hue=labels, ax=ax)ax.set_title('Spectral Embedding')ax.set_xlabel('Eigenvector 1')ax.set_ylabel('Eigenvector 2')plt.show()
/Users/skojaku-admin/miniforge3/envs/advnetsci/lib/python3.11/site-packages/matplotlib/cbook.py:1709: ComplexWarning: Casting complex values to real discards the imaginary part
return math.isfinite(val)
/Users/skojaku-admin/miniforge3/envs/advnetsci/lib/python3.11/site-packages/matplotlib/cbook.py:1709: ComplexWarning: Casting complex values to real discards the imaginary part
return math.isfinite(val)
/Users/skojaku-admin/miniforge3/envs/advnetsci/lib/python3.11/site-packages/pandas/core/dtypes/astype.py:133: ComplexWarning: Casting complex values to real discards the imaginary part
return arr.astype(dtype, copy=True)
/Users/skojaku-admin/miniforge3/envs/advnetsci/lib/python3.11/site-packages/pandas/core/dtypes/astype.py:133: ComplexWarning: Casting complex values to real discards the imaginary part
return arr.astype(dtype, copy=True)
Interestingly, the first eigenvector corresponds to the eigencentrality of the network, representing the centrality of the nodes. The second eigenvector captures the community structure of the network, clearly separating the two communities in the network.
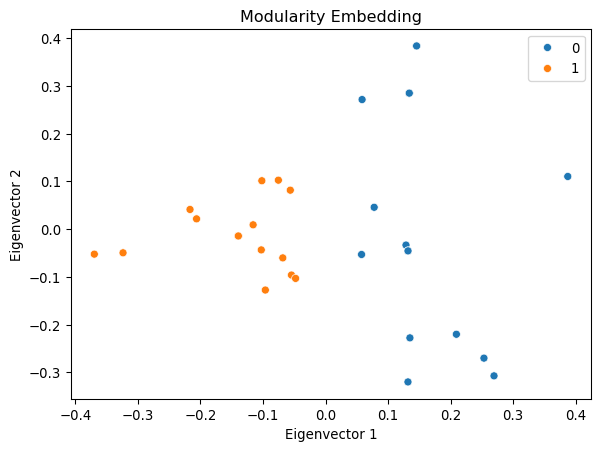
Example: Modularity Embedding
We can use the modularity matrix to generate a low-dimensional embedding of the network.
/Users/skojaku-admin/miniforge3/envs/advnetsci/lib/python3.11/site-packages/matplotlib/cbook.py:1709: ComplexWarning: Casting complex values to real discards the imaginary part
return math.isfinite(val)
/Users/skojaku-admin/miniforge3/envs/advnetsci/lib/python3.11/site-packages/matplotlib/cbook.py:1709: ComplexWarning: Casting complex values to real discards the imaginary part
return math.isfinite(val)
/Users/skojaku-admin/miniforge3/envs/advnetsci/lib/python3.11/site-packages/pandas/core/dtypes/astype.py:133: ComplexWarning: Casting complex values to real discards the imaginary part
return arr.astype(dtype, copy=True)
/Users/skojaku-admin/miniforge3/envs/advnetsci/lib/python3.11/site-packages/pandas/core/dtypes/astype.py:133: ComplexWarning: Casting complex values to real discards the imaginary part
return arr.astype(dtype, copy=True)
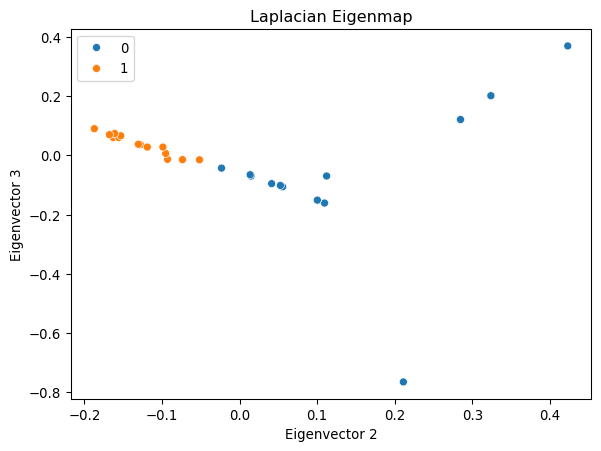
Example: Laplacian Eigenmap
Let us first compute the Laplacian matrix and its eigenvectors.
D = np.diag(np.sum(A_dense, axis=1))L = D - A_denseeigvals, eigvecs = np.linalg.eig(L)# Sort the eigenvalues and eigenvectorssorted_indices = np.argsort(eigvals)[1:d+1] # Exclude the first eigenvectoreigvals = eigvals[sorted_indices]eigvecs = eigvecs[:, sorted_indices]# Plot the resultsfig, ax = plt.subplots(figsize=(7, 5))sns.scatterplot(x = eigvecs[:, 0], y = eigvecs[:, 1], hue=labels, ax=ax)ax.set_title('Laplacian Eigenmap')ax.set_xlabel('Eigenvector 2')ax.set_ylabel('Eigenvector 3')plt.show()
3 Neural Embedding with word2vec
Example: word2vec with Text
To showcase the effectiveness of word2vec, let’s walk through an example using the gensim library.
import gensimimport gensim.downloaderfrom gensim.models import Word2Vec# Load pre-trained word2vec model from Google Newsmodel = gensim.downloader.load('word2vec-google-news-300')
Our first example is to find the words most similar to king.
# Example usageword ="king"similar_words = model.most_similar(word)print(f"Words most similar to '{word}':")for similar_word, similarity in similar_words:print(f"{similar_word}: {similarity:.4f}")
Words most similar to 'king':
kings: 0.7138
queen: 0.6511
monarch: 0.6413
crown_prince: 0.6204
prince: 0.6160
sultan: 0.5865
ruler: 0.5798
princes: 0.5647
Prince_Paras: 0.5433
throne: 0.5422
A cool (yet controversial) application of word embeddings is analogy solving. Let us consider the following puzzle:
man is to woman as king is to ___ ?
We can use word embeddings to solve this puzzle.
# We solve the puzzle by## vec(king) - vec(man) + vec(woman)## To solve this, we use the model.most_similar function, with positive words being "king" and "woman" (additive), and negative words being "man" (subtractive).#model.most_similar(positive=['woman', "king"], negative=['man'], topn=5)
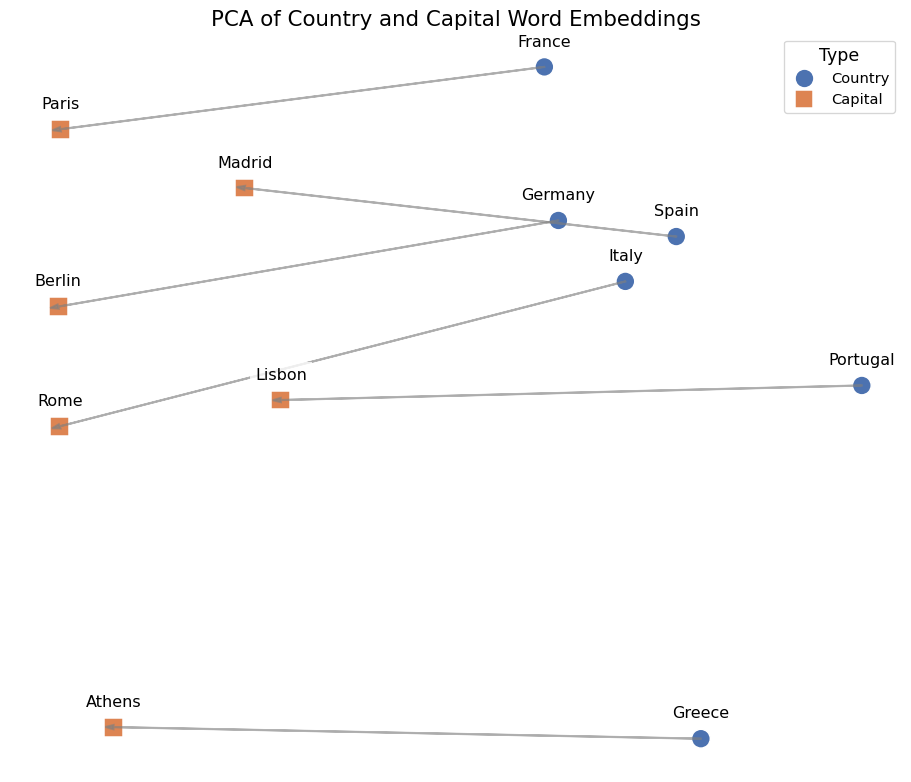
The last example is to visualize the word embeddings.
We can see that word2vec places the words representing countries close to each other and so do the words representing their capitals. The country-capital relationship is also roughly preserved, e.g., Germany-Berlin vector is roughly parallel to France-Paris vector.
4 Graph Embedding with word2vec
DeepWalk: Learning Network Embeddings via Random Walks
DeepWalk treats random walks on a graph as “sentences” and applies word2vec to learn node embeddings. The key insight is that nodes appearing in similar contexts (neighborhoods) should have similar embeddings.
DeepWalk was introduced by Perozzi et al. (2014) and was one of the first methods to successfully apply natural language processing techniques to graph embedding.
Step 1: Generate Random Walks
The first step is to generate training data for word2vec. We do this by sampling random walks from the network. Each random walk is like a “sentence” where nodes are “words”.
Let’s implement a function to sample random walks. A random walk starts at a node and repeatedly moves to a random neighbor until it reaches the desired length.
def random_walk(net, start_node, walk_length):""" Generate a random walk starting from start_node. Parameters: ----------- net : sparse matrix Adjacency matrix of the network start_node : int Starting node for the walk walk_length : int Length of the walk Returns: -------- walk : list List of node indices representing the random walk """ walk = [start_node]whilelen(walk) < walk_length: cur = walk[-1] cur_nbrs =list(net[cur].indices)iflen(cur_nbrs) >0:# Randomly choose one of the neighbors walk.append(np.random.choice(cur_nbrs))else:# Dead end - terminate the walkbreakreturn walk
In practice, we generate multiple walks per node to ensure each node appears in various contexts, which helps the model learn better representations.
Now we generate multiple random walks starting from each node. We’ll use 10 walks per node, each of length 50.
n_nodes = g.vcount()n_walkers_per_node =10walk_length =50walks = []for i inrange(n_nodes):for _ inrange(n_walkers_per_node): walks.append(random_walk(A, i, walk_length))print(f"Generated {len(walks)} random walks")print(f"Example walk: {walks[0][:10]}...") # Show first 10 nodes of first walk
Generated 340 random walks
Example walk: [0, 12, 3, 1, 21, 0, 11, 0, 4, 0]...
Step 2: Train the Word2Vec Model
Now we feed the random walks to the word2vec model. The model will learn to predict which nodes appear together in the same walk, similar to how it learns which words appear together in sentences.
from gensim.models import Word2Vecmodel = Word2Vec( walks, vector_size=32, # Dimension of the embedding vectors window=3, # Maximum distance between current and predicted node min_count=1, # Minimum frequency for a node to be included sg=1, # Use skip-gram model (vs CBOW) hs=1, # Use hierarchical softmax for training, workers =1,)
Key Parameters:
vector_size: Higher dimensions capture more information but require more data and computation.
window: Larger windows capture broader context but may dilute local structure.
sg=1: Skip-gram predicts context from target. It works better for small datasets.
hs=1: Hierarchical softmax is faster than negative sampling for small vocabularies.
The window parameter is crucial. For a random walk [0, 1, 2, 3, 4, 5, 6, 7], when window=3, the context of node 2 includes nodes [0, 1, 3, 4, 5] - all nodes within distance 3.
Step 3: Extract Node Embeddings
After training, we can extract the learned embeddings for each node from the model.
# Extract embeddings for all nodesembedding = np.array([model.wv[i] for i inrange(n_nodes)])print(f"Embedding matrix shape: {embedding.shape}")print(f"First node embedding (first 5 dimensions): {embedding[0][:5]}")
Let’s visualize the learned embeddings in 2D using UMAP (Uniform Manifold Approximation and Projection). UMAP reduces the 32-dimensional embeddings to 2D while preserving the local structure.
UMAP is a dimensionality reduction technique that preserves both local and global structure better than t-SNE, making it ideal for visualizing high-dimensional embeddings.
/Users/skojaku-admin/miniforge3/envs/advnetsci/lib/python3.11/site-packages/umap/umap_.py:1952: UserWarning: n_jobs value 1 overridden to 1 by setting random_state. Use no seed for parallelism.
warn(
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
Loading BokehJS ...
Notice how nodes from the same community (shown in the same color) tend to cluster together in the embedding space. This demonstrates that DeepWalk successfully captures the community structure.
Step 5: Clustering with K-means
One practical application of node embeddings is clustering. While we have dedicated community detection methods like modularity maximization, embeddings allow us to use general machine learning algorithms like K-means.
The advantage of using embeddings is that we can leverage the rich ecosystem of machine learning tools designed for vector data.
Let’s implement K-means clustering with automatic selection of the number of clusters using the silhouette score.
from sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_scoredef find_optimal_clusters(embedding, n_clusters_range=(2, 10)):""" Find the optimal number of clusters using silhouette score. The silhouette score measures how well each node fits within its cluster compared to other clusters. Scores range from -1 to 1, where higher is better. """ silhouette_scores = []for n_clusters inrange(*n_clusters_range): kmeans = KMeans(n_clusters=n_clusters, random_state=42) cluster_labels = kmeans.fit_predict(embedding) score = silhouette_score(embedding, cluster_labels) silhouette_scores.append((n_clusters, score))print(f"k={n_clusters}: silhouette score = {score:.3f}")# Select the number of clusters with highest silhouette score optimal_k =max(silhouette_scores, key=lambda x: x[1])[0]print(f"\nOptimal number of clusters: {optimal_k}")# Perform final clustering with optimal k kmeans = KMeans(n_clusters=optimal_k, random_state=42)return kmeans.fit_predict(embedding)# Find clusterscluster_labels = find_optimal_clusters(embedding)
The silhouette score measures both cohesion (how close nodes are within their cluster) and separation (how far clusters are from each other).
Now let’s visualize the discovered clusters on the network:
# Visualize the clustering resultscmap = sns.color_palette().as_hex()igraph.plot( g, vertex_color=[cmap[label] for label in cluster_labels], bbox=(500, 500), vertex_size=20)
The K-means algorithm successfully identifies community structure using only the learned embeddings, demonstrating that DeepWalk captures meaningful structural properties of the network.
Node2vec: Flexible Graph Embeddings
Node2vec extends DeepWalk by introducing a biased random walk strategy. Instead of uniformly choosing the next node, node2vec uses two parameters, p and q, to control the exploration strategy:
Return parameter p: Controls the likelihood of returning to the previous node
In-out parameter q: Controls whether the walk explores locally (BFS-like) or ventures further (DFS-like)
Node2vec was introduced by Grover and Leskovec (2016). The biased walk allows it to learn embeddings that capture different structural properties depending on the task.
Step 1: Implement Biased Random Walk
The key innovation in node2vec is the biased random walk. Let’s implement it step by step.
def node2vec_random_walk(net, start_node, walk_length, p, q):""" Generate a biased random walk for node2vec. Parameters: ----------- net : sparse matrix Adjacency matrix of the network start_node : int Starting node for the walk walk_length : int Length of the walk p : float Return parameter (controls likelihood of returning to previous node) q : float In-out parameter (controls BFS vs DFS behavior) Returns: -------- walk : list List of node indices representing the biased random walk """ walk = [start_node]whilelen(walk) < walk_length: cur = walk[-1] cur_nbrs =list(net[cur].indices)iflen(cur_nbrs) >0:iflen(walk) ==1:# First step: uniform random choice walk.append(np.random.choice(cur_nbrs))else:# Subsequent steps: biased choice based on p and q prev = walk[-2] next_node = biased_choice(net, cur_nbrs, prev, p, q) walk.append(next_node)else:breakreturn walkdef biased_choice(net, neighbors, prev, p, q):""" Choose the next node with bias controlled by p and q. The transition probability is: - 1/p if returning to the previous node - 1 if moving to a neighbor of the previous node (distance 1) - 1/q if moving away from the previous node (distance 2) """ unnormalized_probs = []for neighbor in neighbors:if neighbor == prev:# Returning to previous node unnormalized_probs.append(1/ p)elif neighbor in net[prev].indices:# Moving to a common neighbor (BFS-like) unnormalized_probs.append(1.0)else:# Moving away from previous node (DFS-like) unnormalized_probs.append(1/ q)# Normalize probabilities norm_const =sum(unnormalized_probs) normalized_probs = [prob / norm_const for prob in unnormalized_probs]# Sample next nodereturn np.random.choice(neighbors, p=normalized_probs)
Understanding p and q:
Small p (p < 1): Encourages returning to previous node, leading to local exploration
Large q (q > 1): Discourages moving away, resulting in BFS-like behavior
Small q (q < 1): Encourages exploration, resulting in DFS-like behavior
Step 2: Generate Walks and Train Model
Now let’s generate biased random walks and train the word2vec model. We’ll use p=1 and q=0.1, which encourages outward exploration (DFS-like behavior) to capture community structure.
# Generate biased random walksp =1.0# Return parameterq =0.1# In-out parameter (q < 1 means DFS-like)walks_node2vec = []for i inrange(n_nodes):for _ inrange(n_walkers_per_node): walks_node2vec.append(node2vec_random_walk(A, i, walk_length, p, q))print(f"Generated {len(walks_node2vec)} biased random walks")print(f"Example walk: {walks_node2vec[0][:10]}...")
Generated 340 biased random walks
Example walk: [0, 6, 16, 5, 10, 4, 6, 16, 6, 0]...
With q=0.1, the walk is 10 times more likely to explore distant nodes than return to the immediate neighborhood, encouraging discovery of global community structure.
Let’s visualize the node2vec embeddings and compare them with DeepWalk.
/Users/skojaku-admin/miniforge3/envs/advnetsci/lib/python3.11/site-packages/umap/umap_.py:1952: UserWarning: n_jobs value 1 overridden to 1 by setting random_state. Use no seed for parallelism.
warn(
Loading BokehJS ...
Notice how the node2vec embeddings with q=0.1 (DFS-like exploration) create even more distinct community clusters compared to DeepWalk. This is because the biased walk explores the community structure more thoroughly.
Step 4: Clustering Analysis
Let’s apply K-means clustering to the node2vec embeddings:
# Find optimal clusters for node2vec embeddingscluster_labels_n2v = find_optimal_clusters(embedding_node2vec)# Visualize the clustering resultsigraph.plot( g, vertex_color=[palette[label] for label in cluster_labels_n2v], bbox=(500, 500), vertex_size=20, vertex_label=[str(i) for i inrange(n_nodes)])
By tuning the p and q parameters, node2vec can adapt to different network analysis tasks - from community detection (small q) to role discovery (large q).
Source Code
---title: "Network Embedding Coding"jupyter: advnetsciexecute: enabled: true---In this section, we implement the embedding methods discussed in the [concepts section](./01-concepts.md).## Data PreparationWe will use the karate club network throughout this notebook.```{python}import numpy as npimport igraphimport matplotlib.pyplot as pltimport seaborn as sns# Load the karate club networkg = igraph.Graph.Famous("Zachary")A = g.get_adjacency_sparse()# Get community labels (Mr. Hi = 0, Officer = 1)labels = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])g.vs["label"] = labels# Visualize the networkpalette = sns.color_palette().as_hex()igraph.plot(g, vertex_color=[palette[label] for label in labels], bbox=(300, 300))```## Spectral Embedding### Example: Spectral Embedding with Adjacency MatrixLet us demonstrate spectral embedding with the karate club network.```{python}# Convert to dense array for eigendecompositionA_dense = A.toarray()``````{python}# Compute the spectral decompositioneigvals, eigvecs = np.linalg.eig(A_dense)# Find the top d eigenvectorsd =2sorted_indices = np.argsort(eigvals)[::-1][:d]eigvals = eigvals[sorted_indices]eigvecs = eigvecs[:, sorted_indices]# Plot the resultsfig, ax = plt.subplots(figsize=(7, 5))sns.scatterplot(x = eigvecs[:, 0], y = eigvecs[:, 1], hue=labels, ax=ax)ax.set_title('Spectral Embedding')ax.set_xlabel('Eigenvector 1')ax.set_ylabel('Eigenvector 2')plt.show()```Interestingly, the first eigenvector corresponds to the eigencentrality of the network, representing the centrality of the nodes.The second eigenvector captures the community structure of the network, clearly separating the two communities in the network.### Example: Modularity EmbeddingWe can use the modularity matrix to generate a low-dimensional embedding of the network.```{python}deg = np.sum(A_dense, axis=1)m = np.sum(deg) /2Q = A_dense - np.outer(deg, deg) / (2* m)Q/=2*meigvals, eigvecs = np.linalg.eig(Q)# Sort the eigenvalues and eigenvectorssorted_indices = np.argsort(-eigvals)[:d]eigvals = eigvals[sorted_indices]eigvecs = eigvecs[:, sorted_indices]fig, ax = plt.subplots(figsize=(7, 5))sns.scatterplot(x = eigvecs[:, 0], y = eigvecs[:, 1], hue=labels, ax=ax)ax.set_title('Modularity Embedding')ax.set_xlabel('Eigenvector 1')ax.set_ylabel('Eigenvector 2')plt.show()```### Example: Laplacian EigenmapLet us first compute the Laplacian matrix and its eigenvectors.```{python}D = np.diag(np.sum(A_dense, axis=1))L = D - A_denseeigvals, eigvecs = np.linalg.eig(L)# Sort the eigenvalues and eigenvectorssorted_indices = np.argsort(eigvals)[1:d+1] # Exclude the first eigenvectoreigvals = eigvals[sorted_indices]eigvecs = eigvecs[:, sorted_indices]# Plot the resultsfig, ax = plt.subplots(figsize=(7, 5))sns.scatterplot(x = eigvecs[:, 0], y = eigvecs[:, 1], hue=labels, ax=ax)ax.set_title('Laplacian Eigenmap')ax.set_xlabel('Eigenvector 2')ax.set_ylabel('Eigenvector 3')plt.show()```## Neural Embedding with word2vec### Example: word2vec with TextTo showcase the effectiveness of word2vec, let's walk through an example using the `gensim` library.```{python}import gensimimport gensim.downloaderfrom gensim.models import Word2Vec# Load pre-trained word2vec model from Google Newsmodel = gensim.downloader.load('word2vec-google-news-300')```Our first example is to find the words most similar to *king*.```{python}# Example usageword ="king"similar_words = model.most_similar(word)print(f"Words most similar to '{word}':")for similar_word, similarity in similar_words:print(f"{similar_word}: {similarity:.4f}")```A cool (yet controversial) application of word embeddings is analogy solving. Let us consider the following puzzle:> *man* is to *woman* as *king* is to ___ ?We can use word embeddings to solve this puzzle.```{python}# We solve the puzzle by## vec(king) - vec(man) + vec(woman)## To solve this, we use the model.most_similar function, with positive words being "king" and "woman" (additive), and negative words being "man" (subtractive).#model.most_similar(positive=['woman', "king"], negative=['man'], topn=5)```The last example is to visualize the word embeddings.```{python}#| echo: falseimport matplotlib.pyplot as pltimport seaborn as snsimport numpy as npimport pandas as pdfrom sklearn.decomposition import PCAcountries = ['Germany', 'France', 'Italy', 'Spain', 'Portugal', 'Greece']capital_words = ['Berlin', 'Paris', 'Rome', 'Madrid', 'Lisbon', 'Athens']# Get the word embeddings for the countries and capitalscountry_embeddings = np.array([model[country] for country in countries])capital_embeddings = np.array([model[capital] for capital in capital_words])# Compute the PCApca = PCA(n_components=2)embeddings = np.vstack([country_embeddings, capital_embeddings])embeddings_pca = pca.fit_transform(embeddings)# Create a DataFrame for seaborndf = pd.DataFrame(embeddings_pca, columns=['PC1', 'PC2'])df['Label'] = countries + capital_wordsdf['Type'] = ['Country'] *len(countries) + ['Capital'] *len(capital_words)# Plot the dataplt.figure(figsize=(12, 10))# Create a scatter plot with seabornscatter_plot = sns.scatterplot(data=df, x='PC1', y='PC2', hue='Type', style='Type', s=200, palette='deep', markers=['o', 's'])# Annotate the pointsfor i inrange(len(df)): plt.text(df['PC1'][i], df['PC2'][i] +0.08, df['Label'][i], fontsize=12, ha='center', va='bottom', bbox=dict(facecolor='white', edgecolor='none', alpha=0.8))# Draw arrows between countries and capitalsfor i inrange(len(countries)): plt.arrow(df['PC1'][i], df['PC2'][i], df['PC1'][i +len(countries)] - df['PC1'][i], df['PC2'][i +len(countries)] - df['PC2'][i], color='gray', alpha=0.6, linewidth=1.5, head_width=0.02, head_length=0.03)plt.legend(title='Type', title_fontsize='13', fontsize='11')plt.title('PCA of Country and Capital Word Embeddings', fontsize=16)plt.xlabel('Principal Component 1', fontsize=14)plt.ylabel('Principal Component 2', fontsize=14)ax = plt.gca()ax.set_axis_off()```We can see that word2vec places the words representing countries close to each other and so do the words representing their capitals. The country-capital relationship is also roughly preserved, e.g., *Germany*-*Berlin* vector is roughly parallel to *France*-*Paris* vector.## Graph Embedding with word2vec### DeepWalk: Learning Network Embeddings via Random WalksDeepWalk treats random walks on a graph as "sentences" and applies word2vec to learn node embeddings. The key insight is that nodes appearing in similar contexts (neighborhoods) should have similar embeddings.::: {.column-margin}DeepWalk was introduced by Perozzi et al. (2014) and was one of the first methods to successfully apply natural language processing techniques to graph embedding.:::#### Step 1: Generate Random WalksThe first step is to generate training data for word2vec. We do this by sampling random walks from the network. Each random walk is like a "sentence" where nodes are "words".Let's implement a function to sample random walks. A random walk starts at a node and repeatedly moves to a random neighbor until it reaches the desired length.```{python}def random_walk(net, start_node, walk_length):""" Generate a random walk starting from start_node. Parameters: ----------- net : sparse matrix Adjacency matrix of the network start_node : int Starting node for the walk walk_length : int Length of the walk Returns: -------- walk : list List of node indices representing the random walk """ walk = [start_node]whilelen(walk) < walk_length: cur = walk[-1] cur_nbrs =list(net[cur].indices)iflen(cur_nbrs) >0:# Randomly choose one of the neighbors walk.append(np.random.choice(cur_nbrs))else:# Dead end - terminate the walkbreakreturn walk```::: {.column-margin}In practice, we generate multiple walks per node to ensure each node appears in various contexts, which helps the model learn better representations.:::Now we generate multiple random walks starting from each node. We'll use 10 walks per node, each of length 50.```{python}n_nodes = g.vcount()n_walkers_per_node =10walk_length =50walks = []for i inrange(n_nodes):for _ inrange(n_walkers_per_node): walks.append(random_walk(A, i, walk_length))print(f"Generated {len(walks)} random walks")print(f"Example walk: {walks[0][:10]}...") # Show first 10 nodes of first walk```#### Step 2: Train the Word2Vec ModelNow we feed the random walks to the word2vec model. The model will learn to predict which nodes appear together in the same walk, similar to how it learns which words appear together in sentences.```{python}from gensim.models import Word2Vecmodel = Word2Vec( walks, vector_size=32, # Dimension of the embedding vectors window=3, # Maximum distance between current and predicted node min_count=1, # Minimum frequency for a node to be included sg=1, # Use skip-gram model (vs CBOW) hs=1, # Use hierarchical softmax for training, workers =1,)```::: {.column-margin}**Key Parameters:**- `vector_size`: Higher dimensions capture more information but require more data and computation.- `window`: Larger windows capture broader context but may dilute local structure.- `sg=1`: Skip-gram predicts context from target. It works better for small datasets.- `hs=1`: Hierarchical softmax is faster than negative sampling for small vocabularies.:::The `window` parameter is crucial. For a random walk `[0, 1, 2, 3, 4, 5, 6, 7]`, when `window=3`, the context of node 2 includes nodes `[0, 1, 3, 4, 5]` - all nodes within distance 3.#### Step 3: Extract Node EmbeddingsAfter training, we can extract the learned embeddings for each node from the model.```{python}# Extract embeddings for all nodesembedding = np.array([model.wv[i] for i inrange(n_nodes)])print(f"Embedding matrix shape: {embedding.shape}")print(f"First node embedding (first 5 dimensions): {embedding[0][:5]}")```#### Step 4: Visualize EmbeddingsLet's visualize the learned embeddings in 2D using UMAP (Uniform Manifold Approximation and Projection). UMAP reduces the 32-dimensional embeddings to 2D while preserving the local structure.::: {.column-margin}UMAP is a dimensionality reduction technique that preserves both local and global structure better than t-SNE, making it ideal for visualizing high-dimensional embeddings.:::```{python}#| echo: falseimport umapfrom bokeh.plotting import figure, showfrom bokeh.io import output_notebookfrom bokeh.models import ColumnDataSource, HoverTool# Reduce embeddings to 2Dreducer = umap.UMAP(n_components=2, random_state=42, n_neighbors=15, metric="cosine")xy = reducer.fit_transform(embedding)output_notebook()# Calculate node degrees for visualizationdegrees = A.sum(axis=1).A1# Create interactive plotsource = ColumnDataSource(data=dict( x=xy[:, 0], y=xy[:, 1], size=np.sqrt(degrees / np.max(degrees)) *30, community=[palette[label] for label in g.vs["label"]]))p = figure(title="DeepWalk Node Embeddings (UMAP projection)", x_axis_label="UMAP 1", y_axis_label="UMAP 2")p.scatter('x', 'y', size='size', source=source, line_color="black", color="community")show(p)```Notice how nodes from the same community (shown in the same color) tend to cluster together in the embedding space. This demonstrates that DeepWalk successfully captures the community structure.#### Step 5: Clustering with K-meansOne practical application of node embeddings is clustering. While we have dedicated community detection methods like modularity maximization, embeddings allow us to use general machine learning algorithms like K-means.::: {.column-margin}The advantage of using embeddings is that we can leverage the rich ecosystem of machine learning tools designed for vector data.:::Let's implement K-means clustering with automatic selection of the number of clusters using the silhouette score.```{python}from sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_scoredef find_optimal_clusters(embedding, n_clusters_range=(2, 10)):""" Find the optimal number of clusters using silhouette score. The silhouette score measures how well each node fits within its cluster compared to other clusters. Scores range from -1 to 1, where higher is better. """ silhouette_scores = []for n_clusters inrange(*n_clusters_range): kmeans = KMeans(n_clusters=n_clusters, random_state=42) cluster_labels = kmeans.fit_predict(embedding) score = silhouette_score(embedding, cluster_labels) silhouette_scores.append((n_clusters, score))print(f"k={n_clusters}: silhouette score = {score:.3f}")# Select the number of clusters with highest silhouette score optimal_k =max(silhouette_scores, key=lambda x: x[1])[0]print(f"\nOptimal number of clusters: {optimal_k}")# Perform final clustering with optimal k kmeans = KMeans(n_clusters=optimal_k, random_state=42)return kmeans.fit_predict(embedding)# Find clusterscluster_labels = find_optimal_clusters(embedding)```::: {.column-margin}The silhouette score measures both cohesion (how close nodes are within their cluster) and separation (how far clusters are from each other).:::Now let's visualize the discovered clusters on the network:```{python}# Visualize the clustering resultscmap = sns.color_palette().as_hex()igraph.plot( g, vertex_color=[cmap[label] for label in cluster_labels], bbox=(500, 500), vertex_size=20)```The K-means algorithm successfully identifies community structure using only the learned embeddings, demonstrating that DeepWalk captures meaningful structural properties of the network.### Node2vec: Flexible Graph EmbeddingsNode2vec extends DeepWalk by introducing a biased random walk strategy. Instead of uniformly choosing the next node, node2vec uses two parameters, $p$ and $q$, to control the exploration strategy:- **Return parameter $p$**: Controls the likelihood of returning to the previous node- **In-out parameter $q$**: Controls whether the walk explores locally (BFS-like) or ventures further (DFS-like)::: {.column-margin}Node2vec was introduced by Grover and Leskovec (2016). The biased walk allows it to learn embeddings that capture different structural properties depending on the task.:::#### Step 1: Implement Biased Random WalkThe key innovation in node2vec is the biased random walk. Let's implement it step by step.```{python}def node2vec_random_walk(net, start_node, walk_length, p, q):""" Generate a biased random walk for node2vec. Parameters: ----------- net : sparse matrix Adjacency matrix of the network start_node : int Starting node for the walk walk_length : int Length of the walk p : float Return parameter (controls likelihood of returning to previous node) q : float In-out parameter (controls BFS vs DFS behavior) Returns: -------- walk : list List of node indices representing the biased random walk """ walk = [start_node]whilelen(walk) < walk_length: cur = walk[-1] cur_nbrs =list(net[cur].indices)iflen(cur_nbrs) >0:iflen(walk) ==1:# First step: uniform random choice walk.append(np.random.choice(cur_nbrs))else:# Subsequent steps: biased choice based on p and q prev = walk[-2] next_node = biased_choice(net, cur_nbrs, prev, p, q) walk.append(next_node)else:breakreturn walkdef biased_choice(net, neighbors, prev, p, q):""" Choose the next node with bias controlled by p and q. The transition probability is: - 1/p if returning to the previous node - 1 if moving to a neighbor of the previous node (distance 1) - 1/q if moving away from the previous node (distance 2) """ unnormalized_probs = []for neighbor in neighbors:if neighbor == prev:# Returning to previous node unnormalized_probs.append(1/ p)elif neighbor in net[prev].indices:# Moving to a common neighbor (BFS-like) unnormalized_probs.append(1.0)else:# Moving away from previous node (DFS-like) unnormalized_probs.append(1/ q)# Normalize probabilities norm_const =sum(unnormalized_probs) normalized_probs = [prob / norm_const for prob in unnormalized_probs]# Sample next nodereturn np.random.choice(neighbors, p=normalized_probs)```::: {.column-margin}**Understanding p and q:**- Small $p$ ($p < 1$): Encourages returning to previous node, leading to local exploration- Large $q$ ($q > 1$): Discourages moving away, resulting in BFS-like behavior- Small $q$ ($q < 1$): Encourages exploration, resulting in DFS-like behavior:::#### Step 2: Generate Walks and Train ModelNow let's generate biased random walks and train the word2vec model. We'll use $p=1$ and $q=0.1$, which encourages outward exploration (DFS-like behavior) to capture community structure.```{python}# Generate biased random walksp =1.0# Return parameterq =0.1# In-out parameter (q < 1 means DFS-like)walks_node2vec = []for i inrange(n_nodes):for _ inrange(n_walkers_per_node): walks_node2vec.append(node2vec_random_walk(A, i, walk_length, p, q))print(f"Generated {len(walks_node2vec)} biased random walks")print(f"Example walk: {walks_node2vec[0][:10]}...")```::: {.column-margin}With $q=0.1$, the walk is 10 times more likely to explore distant nodes than return to the immediate neighborhood, encouraging discovery of global community structure.:::Train the word2vec model on the biased walks:```{python}# Train node2vec modelmodel_node2vec = Word2Vec( walks_node2vec, vector_size=32, window=3, min_count=1, sg=1, hs=1)# Extract embeddingsembedding_node2vec = np.array([model_node2vec.wv[i] for i inrange(n_nodes)])print(f"Node2vec embedding shape: {embedding_node2vec.shape}")```#### Step 3: Visualize Node2vec EmbeddingsLet's visualize the node2vec embeddings and compare them with DeepWalk.```{python}#| echo: false# Reduce node2vec embeddings to 2Dreducer_n2v = umap.UMAP(n_components=2, random_state=42, n_neighbors=15, metric="cosine")xy_n2v = reducer_n2v.fit_transform(embedding_node2vec)output_notebook()degrees = A.sum(axis=1).A1source_n2v = ColumnDataSource(data=dict( x=xy_n2v[:, 0], y=xy_n2v[:, 1], size=np.sqrt(degrees / np.max(degrees)) *30, community=[palette[label] for label in g.vs["label"]], name = [str(i) for i inrange(n_nodes)]))p_n2v = figure(title="Node2vec Embeddings (UMAP projection)", x_axis_label="UMAP 1", y_axis_label="UMAP 2")p_n2v.scatter('x', 'y', size='size', source=source_n2v, line_color="black", color="community")hover = HoverTool()hover.tooltips = [ ("Node", "@name"), ("Community", "@community")]p_n2v.add_tools(hover)show(p_n2v)```Notice how the node2vec embeddings with $q=0.1$ (DFS-like exploration) create even more distinct community clusters compared to DeepWalk. This is because the biased walk explores the community structure more thoroughly.#### Step 4: Clustering AnalysisLet's apply K-means clustering to the node2vec embeddings:```{python}# Find optimal clusters for node2vec embeddingscluster_labels_n2v = find_optimal_clusters(embedding_node2vec)# Visualize the clustering resultsigraph.plot( g, vertex_color=[palette[label] for label in cluster_labels_n2v], bbox=(500, 500), vertex_size=20, vertex_label=[str(i) for i inrange(n_nodes)])```By tuning the $p$ and $q$ parameters, node2vec can adapt to different network analysis tasks - from community detection (small $q$) to role discovery (large $q$).