Doc2Vec: From Words to Documents#
Doc2Vec Model#
Doc2Vec [1] extends word2vec by learning document vectors alongside word vectors. For a document \(d\) with words \(w_1, w_2, ..., w_n\), it learns:
Document vector \(v_d \in \mathbb{R}^m\)
Word vectors \(v_w \in \mathbb{R}^m\)
There are two types of Doc2Vec:
Distributed Memory (PV-DM)
Distributed Bag of Words (PV-DBOW)
where PV-DM corresponds to the CBOW model, and PV-DBOW corresponds to the Skip-Gram model of word2vec.
Note
See the lecture note of word2vec for more details on CBOW and Skip-Gram.
Distributed Memory (PV-DM)#
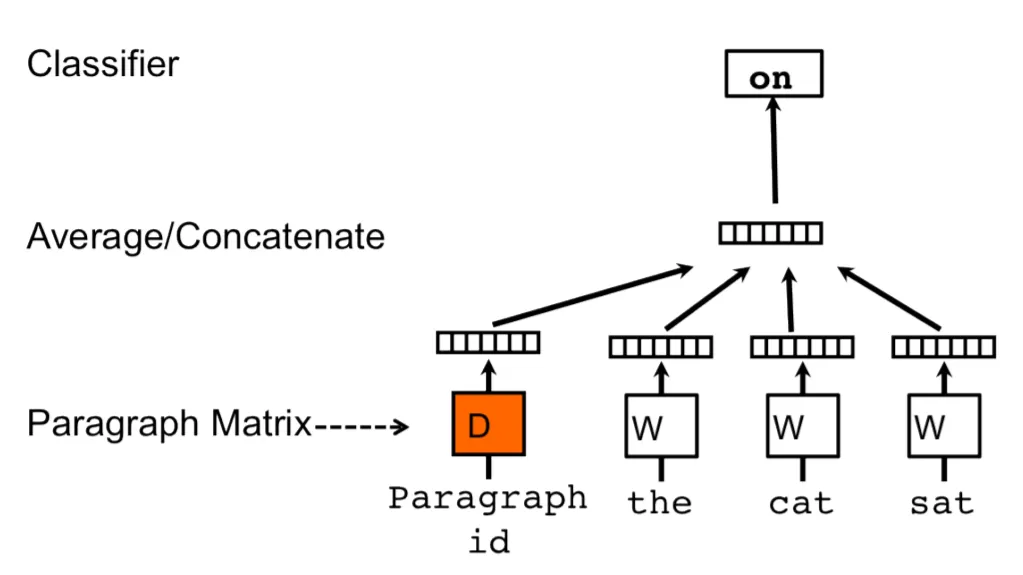
Fig. 1 PV-DM predicts the center word based on the average or concatenated vector of the context words. Image taken from https://heartbeat.comet.ml/getting-started-with-doc2vec-2645e3e9f137#
CBOW word2vec predicts the center word based on the average or concatenated vector of the context words. In PV-DM, the document vector is added to the average or concatenation. More specifically, the probability of a word \(w_i\) given the document \(d\) and the context \(w_{i-k},...,w_{i-1}\) is given by:
where \(h\) is the context vector, which is either the average:
or the concatenation:
where \(U\) is a matrix that maps the concatenated vector (of dimension \(d+kd\)) back to dimension \(d\) to match the word vector space. Here, \(d\) is the embedding dimension and \(k\) is the context window size.
Note
The choice between concatenation and average affects how the document and context vectors are combined:
Average: Treats document vector and context word vectors equally by taking their mean. This is simpler but may neglect the influence of individual context words. No additional parameters needed, making it computationally efficient.
Concatenation: Keeps document and context information separate before combining through the U matrix. This preserves more distinct information but requires learning additional parameters (the U matrix). Though more computationally intensive, it allows the model to learn different weights for document and word contexts. The original paper used concatenation, arguing it allows the model to treat document and word vectors differently.
Warning
The softmax computation over the entire vocabulary V can be computationally expensive for large vocabularies. In practice, optimization techniques like negative sampling or hierarchical softmax are commonly used to approximate this computation more efficiently.
Distributed Bag of Words (PV-DBOW)#
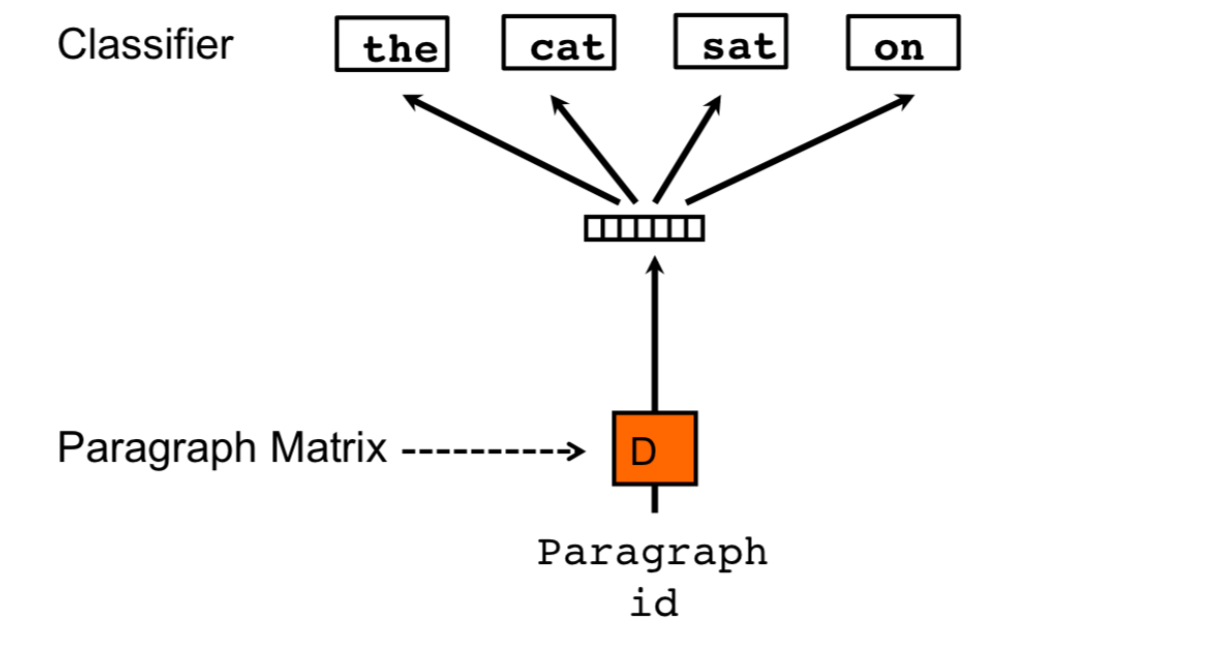
Fig. 2 PV-DBOW predicts context words using only the document vector, similar to Skip-Gram predicting context words from a center word. Image taken from https://heartbeat.comet.ml/getting-started-with-doc2vec-2645e3e9f137#
PV-DBOW is similar to Skip-Gram. The probability of a word \(w_i\) given the document \(d\) is given by:
This is analogous to the skip-gram model, where the document vector \(v_d\) is used to predict the context words.
Note
Which mode, PV-DM or PV-DBOW, is better? The original paper [1] suggests that PV-DM is better, since it can distinguish the order of words within a document. Yet, [2] found that PV-DBOW, despite being more simple, is better overall for document similarity tasks, when properly tuned. This highlights the importance of hyperparameter optimization in practice.
Key considerations for choosing between PV-DM and PV-DBOW:
PV-DM: Better for tasks requiring word order sensitivity
PV-DBOW: More efficient training, often better for similarity tasks
Hybrid approach: Some implementations combine both methods
Hands-on Implementation#
Let us have a hands-on implementation of Doc2Vec using the gensim library.
Our sample documents are:
# Sample documents
documents = [
"Machine learning is a subset of artificial intelligence",
"Deep learning uses neural networks with multiple layers",
"Natural language processing deals with text and speech",
"Computer vision focuses on image and video analysis",
"Reinforcement learning involves agents making decisions"
]
We will first import the necessary libraries.
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from nltk.tokenize import word_tokenize
In gensim doc2vec, we need to prepare the documents in the form of TaggedDocument.
# Prepare documents
tagged_docs = []
for i, doc in enumerate(documents):
tagged_doc = TaggedDocument(
words=word_tokenize(doc.lower()), # tokenize the document
tags=[str(i)] # tag the document with its index
)
tagged_docs.append(tagged_doc)
We added “tags” along with the words. The “tag” is used to identify the document.
Tip
word_tokenize is a function from the nltk library that tokenizes the document into words.
For example, “Machine learning is a subset of artificial intelligence” is tokenized into ['machine', 'learning', 'is', 'a', 'subset', 'of', 'artificial', 'intelligence'].
Second, we need to train the Doc2Vec model.
# Train Doc2Vec model
model = Doc2Vec(tagged_docs,
vector_size=50, # dimension of the document vector
window=2, # context window size
min_count=1, # ignore words that appear less than this
epochs=300,
dm=1, # 0: PV-DBOW, 1: PV-DM
)
# Common hyperparameters to tune:
# - vector_size: Higher dimensions can capture more complex relationships but need more data
# - window: Larger windows capture broader context but increase computation
# - dm_concat: 1 for concatenation, 0 for averaging in PV-DM
# - negative: Number of negative samples (default: 5)
# - alpha: Initial learning rate
This generates the model along with the word and document vectors.
One of the interesting features of Doc2Vec is that it can generate an embedding for a new unseen document.
This can be done by using the infer_vector method.
Tip
A new document vector is generated by fixing the word vectors and optimizing the document vector through gradient descent. The inference process:
Initialize a random document vector
Perform gradient updates using the pre-trained word vectors
Return the optimized document vector See [1] for more details.
# Find similar documents
test_doc = "AI systems use machine learning algorithms"
test_vector = model.infer_vector(word_tokenize(test_doc.lower()))
Now, let us find the most similar documents to the test document.
similar_docs = model.dv.most_similar([test_vector])
print("Similar documents to:", test_doc, "\n")
for doc_id, similarity in similar_docs:
print(f"Document {doc_id}: {documents[int(doc_id)]}")
print(f"Similarity: {similarity:.4f}\n")
Similar documents to: AI systems use machine learning algorithms
Document 0: Machine learning is a subset of artificial intelligence
Similarity: 0.9842
Document 2: Natural language processing deals with text and speech
Similarity: 0.9803
Document 1: Deep learning uses neural networks with multiple layers
Similarity: 0.9698
Document 3: Computer vision focuses on image and video analysis
Similarity: 0.9667
Document 4: Reinforcement learning involves agents making decisions
Similarity: 0.9577
🔥 Exercises 🔥#
Create a search engine using Doc2Vec. This search engine takes a query document and returns the most similar documents.
Perform topic classification based on the document vectors.
Visualization Challenge
Create t-SNE/UMAP/PCA visualization of the document vectors.
Color-code by topic
Analyze clustering patterns
sample_documents = [
# Technology
{"text": "Artificial intelligence is transforming the way we interact with computers", "topic": "technology"},
{"text": "Machine learning algorithms can identify patterns in complex datasets", "topic": "technology"},
{"text": "Deep learning models have achieved human-level performance in image recognition", "topic": "technology"},
{"text": "Neural networks are inspired by biological brain structures", "topic": "technology"},
{"text": "Natural language processing enables machines to understand human text", "topic": "technology"},
{"text": "Computer vision systems can detect objects in real-time video streams", "topic": "technology"},
{"text": "Reinforcement learning agents learn through interaction with environments", "topic": "technology"},
{"text": "Edge computing brings AI processing closer to data sources", "topic": "technology"},
{"text": "Transfer learning reduces the need for large training datasets", "topic": "technology"},
{"text": "Automated machine learning optimizes model architecture search", "topic": "technology"},
{"text": "Explainable AI helps understand model decision-making processes", "topic": "technology"},
{"text": "Federated learning enables privacy-preserving model training", "topic": "technology"},
{"text": "Quantum computing promises breakthroughs in optimization problems", "topic": "technology"},
{"text": "Cloud platforms provide scalable computing resources", "topic": "technology"},
{"text": "GPUs accelerate deep learning model training significantly", "topic": "technology"},
# Science
{"text": "Quantum mechanics explains behavior at the atomic scale", "topic": "science"},
{"text": "DNA sequencing reveals genetic variations between organisms", "topic": "science"},
{"text": "Chemical reactions transfer energy between molecules", "topic": "science"},
{"text": "Gravitational waves provide insights into cosmic events", "topic": "science"},
{"text": "Particle accelerators probe fundamental physics laws", "topic": "science"},
{"text": "Cell biology studies the basic units of life", "topic": "science"},
{"text": "Evolutionary theory explains species adaptation", "topic": "science"},
{"text": "Neuroscience investigates brain structure and function", "topic": "science"},
{"text": "Climate models predict long-term weather patterns", "topic": "science"},
{"text": "Geological processes shape Earth's surface features", "topic": "science"},
{"text": "Conservation biology aims to protect endangered species", "topic": "science"},
{"text": "Astronomy studies celestial objects and phenomena", "topic": "science"},
{"text": "Biochemistry examines cellular metabolic processes", "topic": "science"},
{"text": "Physics laws describe fundamental force interactions", "topic": "science"},
{"text": "Scientific method tests hypotheses through experiments", "topic": "science"},
# Business
{"text": "Market analysis guides investment decisions", "topic": "business"},
{"text": "Strategic planning sets long-term company goals", "topic": "business"},
{"text": "Financial reports track business performance metrics", "topic": "business"},
{"text": "Supply chain optimization reduces operational costs", "topic": "business"},
{"text": "Customer relationship management builds loyalty", "topic": "business"},
{"text": "Digital marketing reaches targeted audiences online", "topic": "business"},
{"text": "Product development responds to market demands", "topic": "business"},
{"text": "Risk management protects business assets", "topic": "business"},
{"text": "Human resources develops employee talent", "topic": "business"},
{"text": "Sales strategies drive revenue growth", "topic": "business"},
{"text": "Competitive analysis identifies market opportunities", "topic": "business"},
{"text": "Business analytics inform decision-making processes", "topic": "business"},
{"text": "Brand management builds company reputation", "topic": "business"},
{"text": "Operations management streamlines production processes", "topic": "business"},
{"text": "Innovation strategy drives business transformation", "topic": "business"}
]