From Language Model to Instruction-Following#
Autoregressive models such as GPT-2 generate text sequentially, predicting each new token based entirely on previous context. While GPT-2 can produce impressively coherent text, it fundamentally lacks the capability to interpret prompts as explicit instructions. Instead, it treats input prompts merely as initial conditions for text generation, limiting precise user control over the generated content.
For instance, prompting GPT-2 with the phrase:
“Translate the following sentence into French: ‘How are you?’”
might lead to GPT-2 continuing the prompt with a conversational response or explanation rather than providing a direct translation.
Transition to Meta-Learning: Google’s T5 Model#
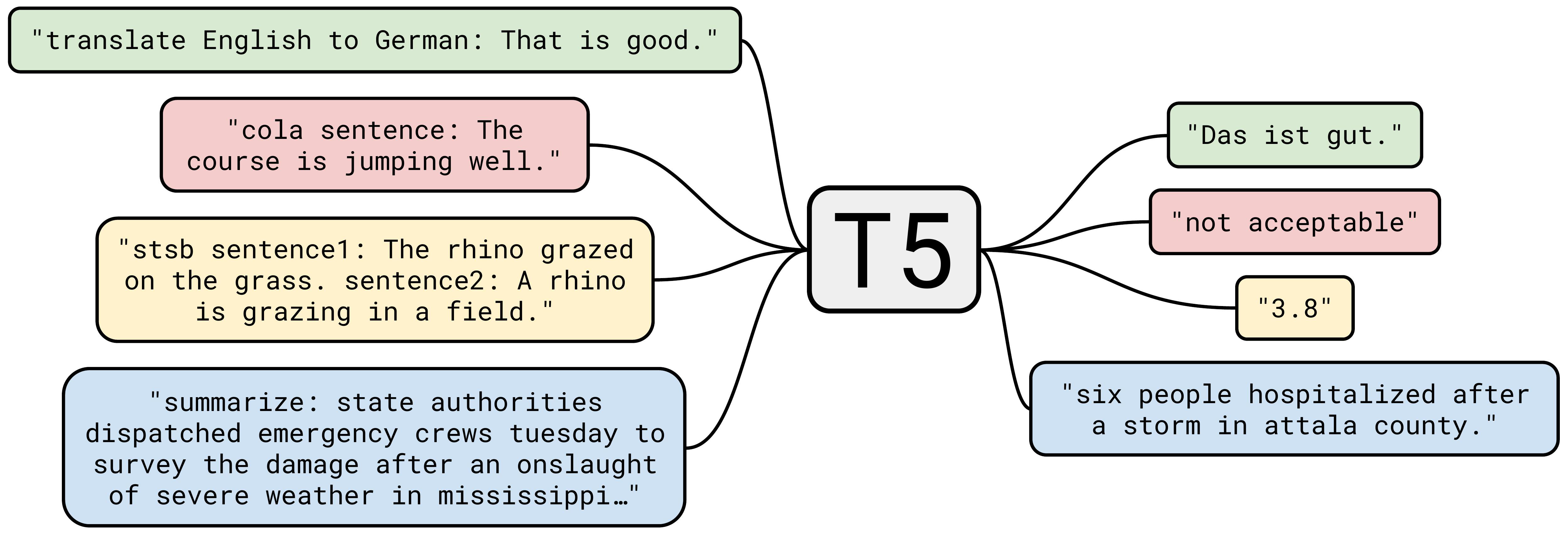
Recognizing the inherent limitations of GPT-2 and purely autoregressive models, researchers moved toward frameworks that explicitly interpret prompts as structured instructions rather than mere context. Google’s Text-to-Text Transfer Transformer (T5) marked a pivotal step in this evolution.
Unlike GPT-2, which generates text solely by predicting the next token based on preceding context, T5 was designed using a unified text-to-text approach. Every NLP task—whether translation, summarization, sentiment analysis, or question-answering—was transformed into text-to-text tasks. And the model is trained on multiple tasks specified in the prompt. This is crucial. Training on a single task does not require model to understand the instruction. Training on multiple tasks means that “understanding a given instruction” is a part of the training objective.
T5 paper:
The paper on T5 is an important milestone in the development of language models. It succinctly summarizes the key ideas developed in the past. By comparing the effectiveness of different ideas, the authors rationalized the design choices of T5 they have made. I highly recommend to read the paper since it is very rewarding, and you can grasp the big picture of the development of language models.
[1910.10683] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
You can also find my summary of the paper in the Appendix.
Instruction Fine-Tuning: The Emergence of FLAN-T5#
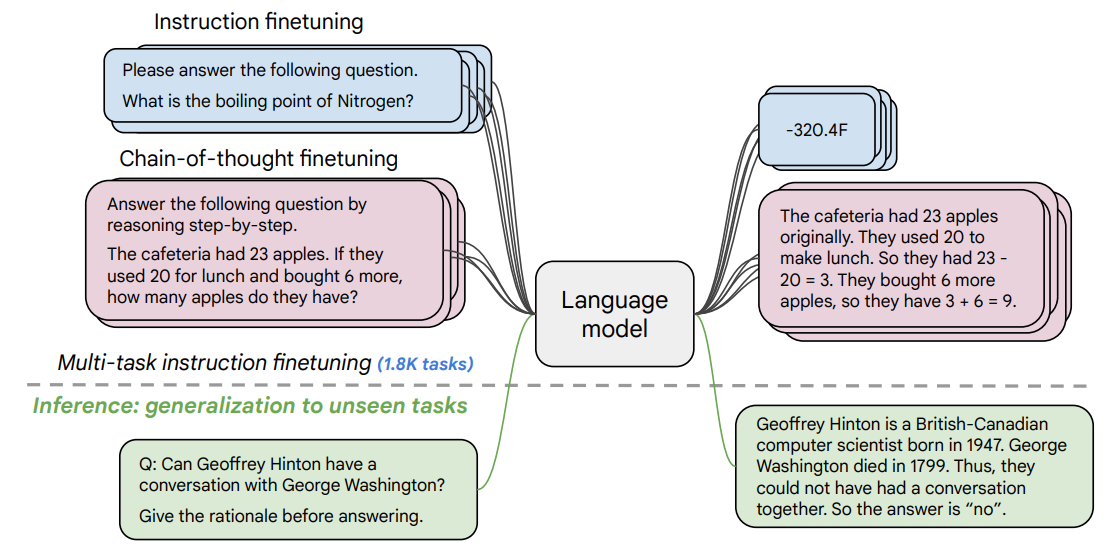
While meta-learning made a big step forward, challenge still remains. T5 is like an old version of Siri that can only follow the rigid task specifications in predefined formats (e.g., “translate:”, “summarize:”), limiting user interaction flexibility. This is attributed to:
Limited instruction diversity: T5 was trained on a relatively narrow set of task formats and instruction patterns, making it struggle with novel phrasings or complex instructions.
Poor generalization to unseen tasks: The model couldn’t effectively transfer its instruction-following capabilities to tasks outside its training distribution.
Rigid interpretation: T5 often interpreted instructions literally rather than understanding the underlying intent, leading to brittle performance when instructions varied slightly.
Lack of nuance in responses: Outputs tended to follow templated patterns rather than adapting to the specific nuances requested in instructions.
FLAN-T5 (Fine-tuned Language Net - T5) represents a pivotal step towards more flexible and nuanced instruction following. The critical difference between T5 and FLAN-T5 is how they handle instructions: T5 understood basic task types but had limited flexibility in instruction formats, whereas FLAN-T5 was explicitly fine-tuned to comprehend and follow diverse, detailed natural language instructions.
For instance, instead of simply recognizing “summarize:” as a task identifier, FLAN-T5 can interpret and execute nuanced prompts like: “Provide a two-sentence summary highlighting the main causes of climate change mentioned in this paragraph.” This fine-tuning enables FLAN-T5 to understand instructions with significantly more depth and variation than its predecessor.
Reinforcement Learning with Human Feedback (RLHF)#
Building on instruction fine-tuning, Reinforcement Learning with Human Feedback (RLHF) emerged as a powerful technique designed to align model outputs more closely with human expectations and preferences. RLHF integrates human evaluations into a reinforcement learning framework, creating a feedback loop where model outputs are continually refined based on direct human judgment.
In RLHF, human evaluators review model-generated outputs, rating or ranking them according to accuracy, coherence, appropriateness, or other desired characteristics. These human-generated scores guide the model’s reinforcement learning algorithm to adjust its responses iteratively, allowing it to increasingly reflect nuanced human values and preferences.
Concrete Example:
Consider a language model tasked with answering the question: “What are some healthy snacks?”
Initial Output:
"Candy bars and potato chips."
Human Feedback: Low rating (unhealthy options)
Subsequent Output (After RLHF):
"Fresh fruit, nuts, yogurt, or vegetables with hummus."
Human Feedback: High rating (appropriate and accurate)
The model gradually learns to produce outputs aligned with human preferences through repeated cycles of evaluation and feedback.
Here is a good blog about RLHF: Reinforcement Learning from Human Feedback (RLHF) - a simplified explanation · GitHub