Sequence-to-Sequence Models#
A key limitation of LSTM networks is that they process text word-by-word, rather than considering the full context of a sentence. This becomes particularly problematic when translating between languages with different grammatical structures. For instance, English and Japanese have vastly different word orders - while English follows a subject-verb-object pattern, Japanese typically places the verb at the end of the sentence.
The need to transform sequences appears frequently in modern computing applications, from speech-to-text conversion to document summarization. To address these challenges and overcome the limitations of traditional LSTMs, researchers developed sequence-to-sequence models as a more effective solution.
Overview#
Sequence-to-sequence (seq2seq) models [1] are family of neural networks that take a sequence as input and generate another sequence as output. Sequence-to-sequence models consist of two parts: the encoder and the decoder.
Encoder: reads the input sequence and compresses it into a context vector, which captures the meaning and nuances of the input.
Decoder: takes this fixed-size context vector and generates a completely new sequence autoregressively, potentially of different length and in a different format altogether.
The encoder and decoder are connected through a context vector, which is a fixed-size vector that captures the meaning and nuances of the input sequence. The context vector is used to initialize the decoder state, and the decoder uses it to generate the output sequence. The encoder and decoder are recurrent neural networks that can be implemented using LSTM or similar RNN modles.
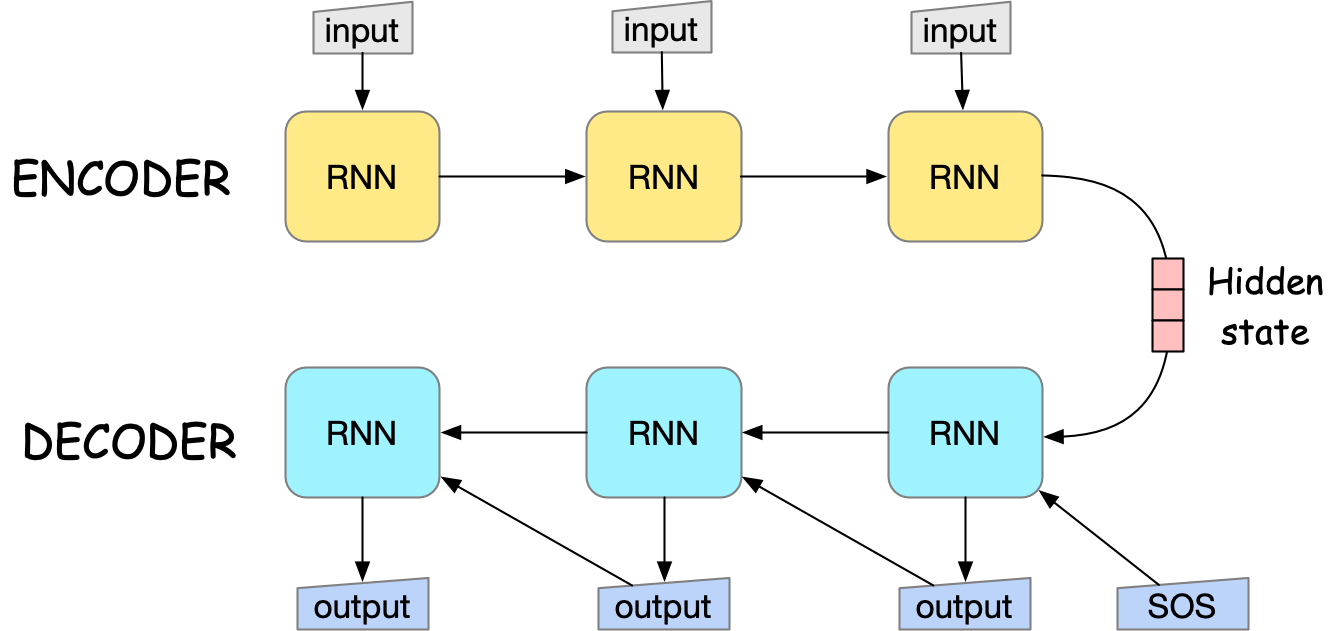
Fig. 14 seq2seq model architecture. The last hidden state of the encoder is used to initialize the decoder state. [SOS] is the start-of-sequence token that indicates the beginning of the output sequence.#
Pay attention!#
Two papers [2] and [3] proposed what is now known as the attention mechanism, which is a key innovation of seq2seq models.
One of the key limitation of the seq2seq model is that the context vector has a fixed size, which creates an information bottleneck, especially for long sequences where important details can be lost during compression.
In attention mechanism, we pass, instead of the last hidden state of the encoder, all the hidden states of the encoder to the decoder. This resolves the information bottleneck problem.
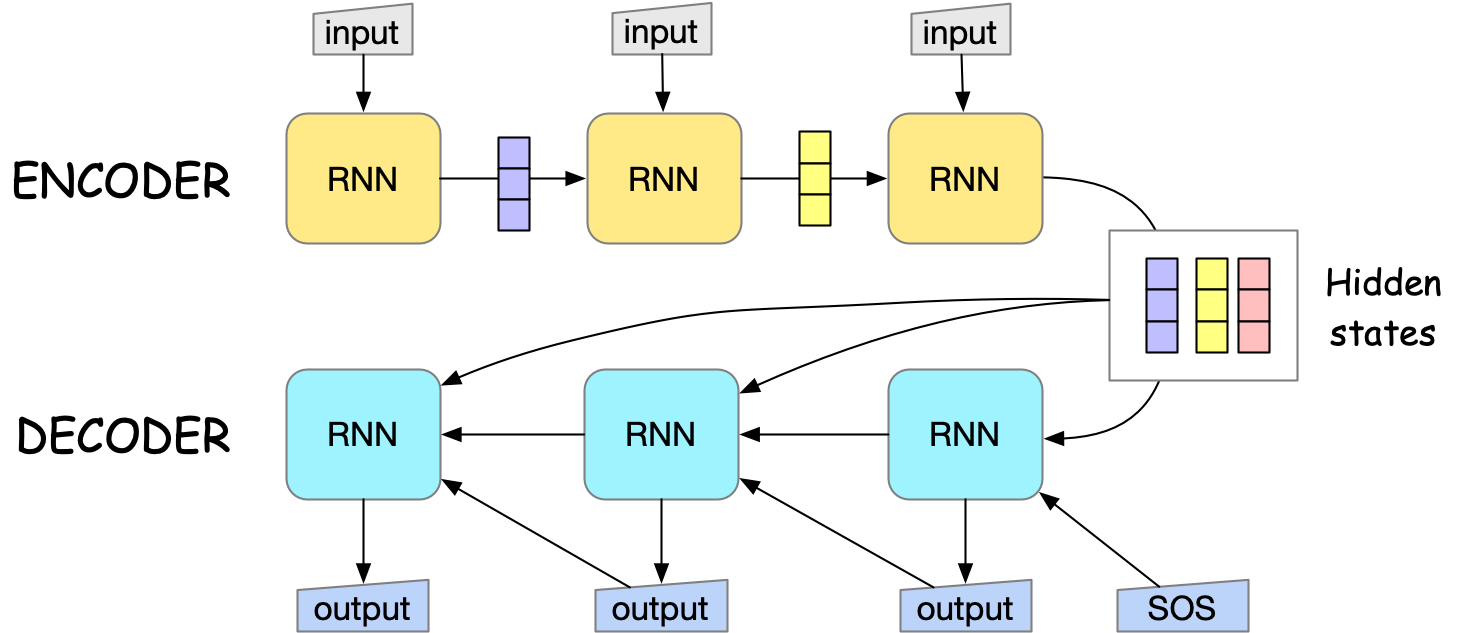
Fig. 15 seq2seq model architecture with attention mechanism. All the hidden states of the encoder are passed to the decoder.#
Now, let’s focus on the decoder processing the word at time \(t\). While we give the decoder all the hidden states of the encoder, not all of them are relevant to the decoding process for the word at time \(t\). Thus, the decoder first identifies the relevance between each hidden state \(h_j\) of the encoder and the current hidden state \(s_{t-1}\) of the decoder.
where \(f\) is a scoring function, often implemented as a neural network, that computes the relevance between the decoder hidden state \(s_{t-1}\) and the encoder hidden state \(h_j\). For example, the following figure represents a neural network consisting of one hidden layer with a tanh activation.
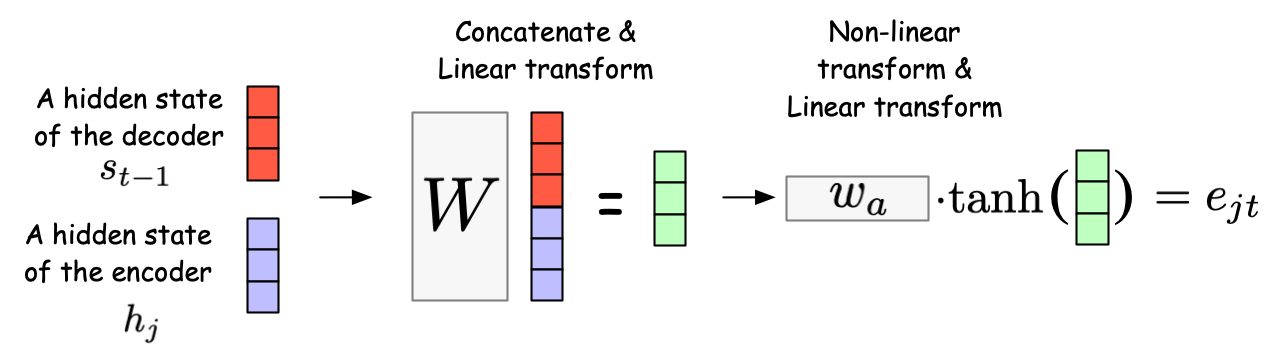
Fig. 16 The neural network that computes the relevance between the decoder hidden state \(s_{t-1}\) and the encoder hidden state \(h_j\).#
\(e_{tj}\) is then normalized using the softmax function to obtain the attention weights \(\alpha_{tj}\):
The attention weights \(\alpha_{tj}\) are then used to compute the context vector \(c_t\) as a weighted sum of the encoder hidden states \(h_j\) using the attention weights \(\alpha_{tj}\):
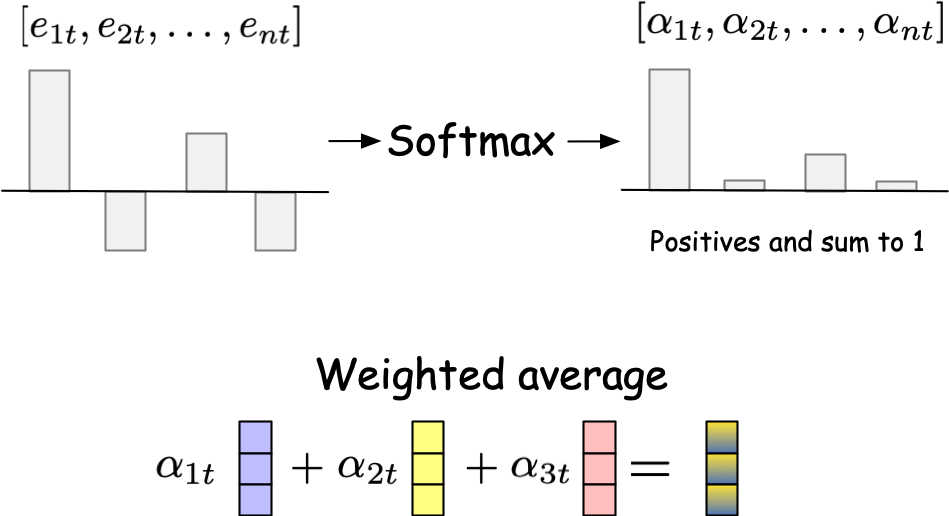
Fig. 17 How the new context vector \(c_t\) is computed as a weighted sum of the encoder hidden states \(h_j\) using the attention weights \(\alpha_{tj}\).#
Note
This is a visualization of how sequence-to-sequence models with attention mechanism works.
Hands on#
Training a seq2seq model with attention mechanism is a challenging but fun exercise through which you will learn so many things like how to adjust tensor shapes, teacher forcing, and how to put together different components of PyTorch (Linear, GRU, LSTM, Embedding, etc.). This is a very rewarding experience, and I highly recommend implementing it yourself if you want to develop practical ML engineering skills.
Interested students can try the following hands on edxercise:
seq2seq.ipynb. This is a hands-on exercise to implement a seq2seq model with attention mechanism for deciphering a simple cipher.
NLP From Scratch: Translation with a Sequence to Sequence Network and Attention — PyTorch Tutorials 2.5.0+cu124 documentation. This is a PyTorch tutorial to implement a seq2seq model with attention mechanism for machine translation.