AlexNet: A Breakthrough in Deep Learning#
How can we train a computer to recognize 1000 different types of objects across more than a million images, and what makes this problem so challenging?
AlexNet in interactive mode:
Here is a demo notebook for AlexNet
To run the notebook, download the notebook as a .py file and run it with:
marimo edit –sandbox alexnet.py
You will need to install marimo and uv to run the notebook. But other packages will be installed automatically in uv’s virtual environment.
Conceptual Foundation: The ImageNet Challenge#
Before diving into AlexNet, let’s explore why large-scale image classification posed such a formidable problem for machine learning:
Massive Dataset: The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) dataset contains over 1.2 million training images labeled across 1000 categories.
Computational Demands: Traditional approaches struggled both with the sheer volume of data and with the complexity of designing handcrafted features.
Error Plateaus: Prior to 2012, the best error rates hovered around 25%, suggesting that existing methods had nearly peaked using conventional feature-engineering techniques.

Fig. 59 The ImageNet Large Scale Visual Recognition Challenge (ILSVRC).#
Tip
Prior to AlexNet, most computer vision systems relied on hand-engineered features such as SIFT (Scale-Invariant Feature Transform) or HOG (Histogram of Oriented Gradients). These were labor-intensive to design and often failed to generalize well to diverse images.
In 2012, a team led by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton demonstrated a deep Convolutional Neural Network (CNN) that shattered expectations. Their submission, known as AlexNet, reduced the top-5 error rate to 16.4%—a remarkable improvement of over 10 percentage points compared to the next-best approach [1].
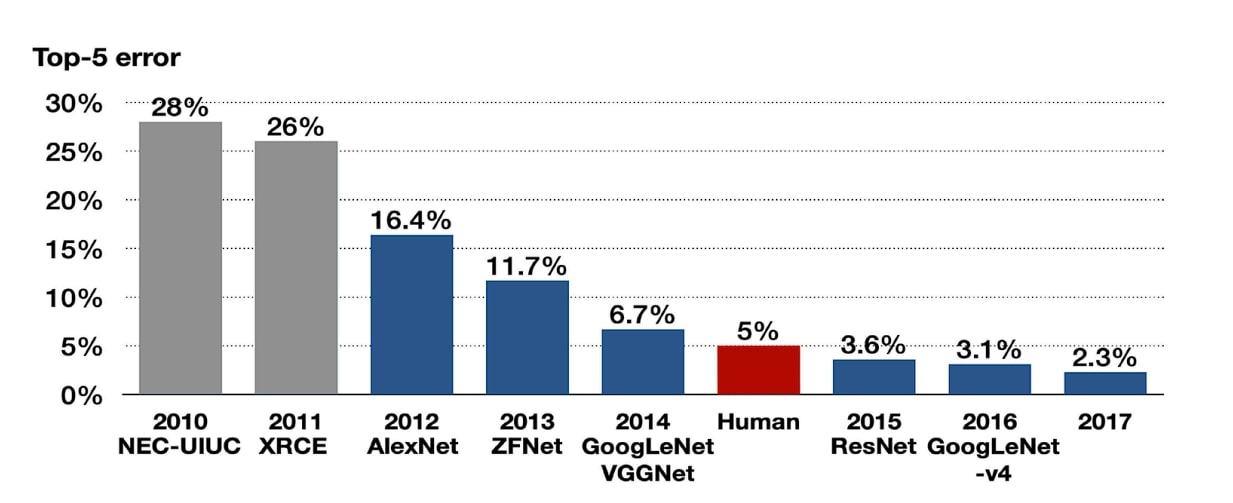
Fig. 60 Top 5 error rates of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) from 2010 to 2017. AlexNet reduced the error rate by over 10 percentage points compared to the best performing method based on human-crafted features in 2011.#
This breakthrough ignited the deep learning revolution in computer vision. Researchers quickly realized the potential of stacking many layers of neural networks—provided they could overcome critical hurdles in training and regularization.
Key Innovations in AlexNet#
ReLU Activation Function#
The Challenge: Deep neural networks often suffer from the vanishing gradient problem, making early layers in the network extremely hard to train. Common activation functions like the sigmoid:
suffer from saturation, where the gradient becomes almost zero if the input \(x\) is large (positive or negative).
The AlexNet Solution: Introduce the Rectified Linear Unit (ReLU) [2]:

Fig. 61 Sigmoid vs. ReLU activation functions. Sigmoid can cause gradients to vanish for \(x\) far from zero, whereas ReLU maintains a constant gradient (1) for \(x>0\).#
Benefits:
Avoids vanishing gradients for positive \(x\).
Computationally efficient: Only a simple check if \(x>0\).
Drawback:
Neurons can “die” (always output zero) if \(x\) stays negative. Variants like Leaky ReLU or Parametric ReLU (PReLU) introduce a small slope for \(x \leq 0\) to mitigate this.
Note
Leaky ReLU/PReLU are typically defined as:
where \(\alpha\) is a small positive constant.
Dropout Regularization#
Deep networks with millions of parameters can easily overfit to the training data, harming their ability to generalize.
The AlexNet solution is to use Dropout [3], a technique that randomly disables (or “drops out”) neurons with probability \(p\) during training.
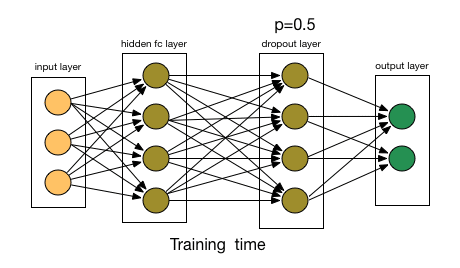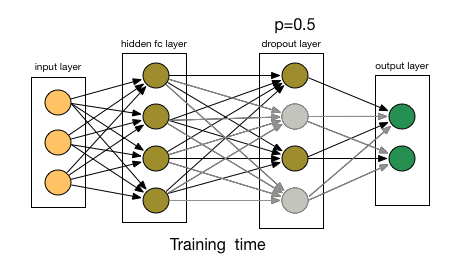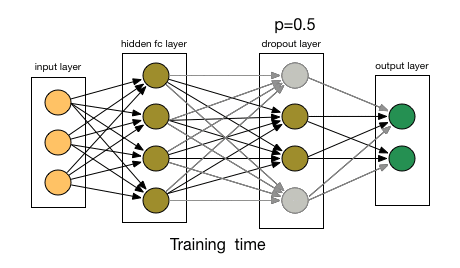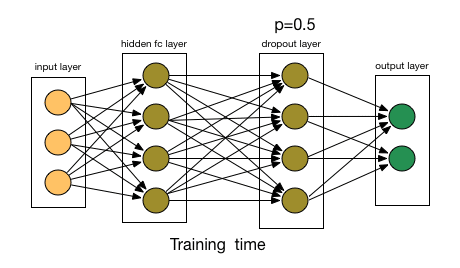
Fig. 62 Dropout in action.#
Training: Each neuron is “dropped” with probability \(p\), forcing the network to not rely on any single neuron’s output.
Inference: All neurons are used, but their outputs are scaled by \((1-p)\) to maintain expected values.
Note
An alternative known as inverse dropout scales weights by \(1/(1-p)\) during training, removing the need for scaling during inference. This is how many popular deep learning frameworks (e.g., TensorFlow) implement dropout.
3. Local Response Normalization (LRN)#
In CNNs, neighboring feature maps can become disproportionately large, leading to unstable or less discriminative representations.
In the AlexNet, this is rectified by Local Response Normalization (LRN) , which normalizes activity across adjacent channels:
Here, (a^i_{x,y}) is the activation at channel (i), and (k, \alpha, \beta, n) are constants. LRN encourages local competition among adjacent channels, akin to certain neural mechanisms in biological systems.
Note
LRN is less commonly used in modern architectures (like VGG, ResNet, etc.) which often rely on batch normalization or other normalization techniques. Still, LRN was a key component in AlexNet’s success at the time.
The AlexNet Architecture#
Now that we’ve seen how AlexNet addressed vanishing gradients, overfitting, and feature-map normalization, let’s look at the overall blueprint:
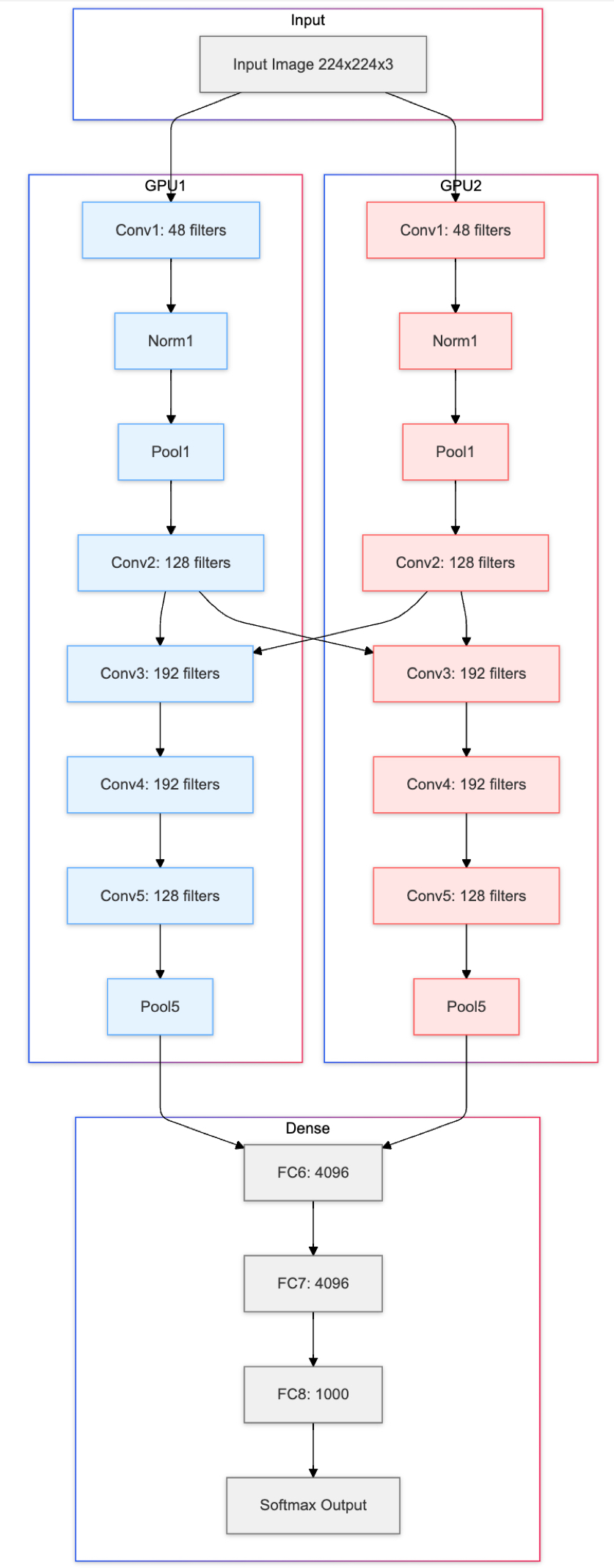
Fig. 63 A high-level view of the AlexNet architecture.#
Detailed Layer-by-Layer Overview:
Input: 3-channel color image, 224×224 pixels
Conv1: [11×11, stride=4, padding=2] → ReLU → LRN → Overlapping Max Pool ([3×3], stride=2)
Conv2: [5×5, stride=1, padding=2] → ReLU → LRN → Overlapping Max Pool ([3×3], stride=2)
Conv3: [3×3, stride=1, padding=1] → ReLU
Conv4: [3×3, stride=1, padding=1] → ReLU
Conv5: [3×3, stride=1, padding=1] → ReLU → Overlapping Max Pool ([3×3], stride=2)
FC6: Flatten → 9216 → 4096 → ReLU → Dropout
FC7: 4096 → 4096 → ReLU → Dropout
FC8: 4096 → 1000 → Softmax Output
Tip
Parallel GPU Computation AlexNet was trained on two GPUs with 3GB of memory each, splitting feature maps between them to handle the large parameter count. This approach showcased the necessity and practicality of GPU computing for large-scale deep learning.
Implementation Example#
Below is a minimal snippet illustrating how one might instantiate an AlexNet-like model using PyTorch’s built-in module. For a step-by-step tutorial, check out Writing AlexNet from Scratch in PyTorch | DigitalOcean.
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleAlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(SimpleAlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
# LRN is omitted in modern PyTorch models, replaced by batch norm or left out
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
# Another LRN placeholder if needed
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# Instantiate the model
model = SimpleAlexNet(num_classes=1000)
print(model)
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[1], line 1
----> 1 import torch
2 import torch.nn as nn
3 import torch.nn.functional as F
File ~/miniforge3/envs/applsoftcomp/lib/python3.10/site-packages/torch/__init__.py:367
365 if USE_GLOBAL_DEPS:
366 _load_global_deps()
--> 367 from torch._C import * # noqa: F403
370 class SymInt:
371 """
372 Like an int (including magic methods), but redirects all operations on the
373 wrapped node. This is used in particular to symbolically record operations
374 in the symbolic shape workflow.
375 """
ImportError: dlopen(/Users/skojaku-admin/miniforge3/envs/applsoftcomp/lib/python3.10/site-packages/torch/_C.cpython-310-darwin.so, 0x0002): Symbol not found: __ZN2at3cpu20is_arm_sve_supportedEv
Referenced from: <D93D20A5-7F4C-32F1-874B-FE7B416FFD91> /Users/skojaku-admin/miniforge3/envs/applsoftcomp/lib/python3.10/site-packages/torch/lib/libtorch_python.dylib
Expected in: <616791F0-29C3-3F88-8A88-D072E7E40979> /Users/skojaku-admin/miniforge3/envs/applsoftcomp/lib/libtorch_cpu.dylib
In practice, PyTorch provides a pre-trained version of AlexNet via torchvision.models.alexnet. You can load it with:
import torchvision.models as models
alexnet = models.alexnet(pretrained=True)