instruction = "Summarize this abstract"
data = """
We develop a graph neural network for predicting protein-protein interactions
from sequence data. Our model uses attention mechanisms to identify functionally
important amino acid subsequences. We achieve 89% accuracy on benchmark datasets,
outperforming previous methods by 7%. The model also provides interpretable
attention weights showing which protein regions drive predictions.
"""
prompt = f"{instruction}. {data}"Prompt Tuning
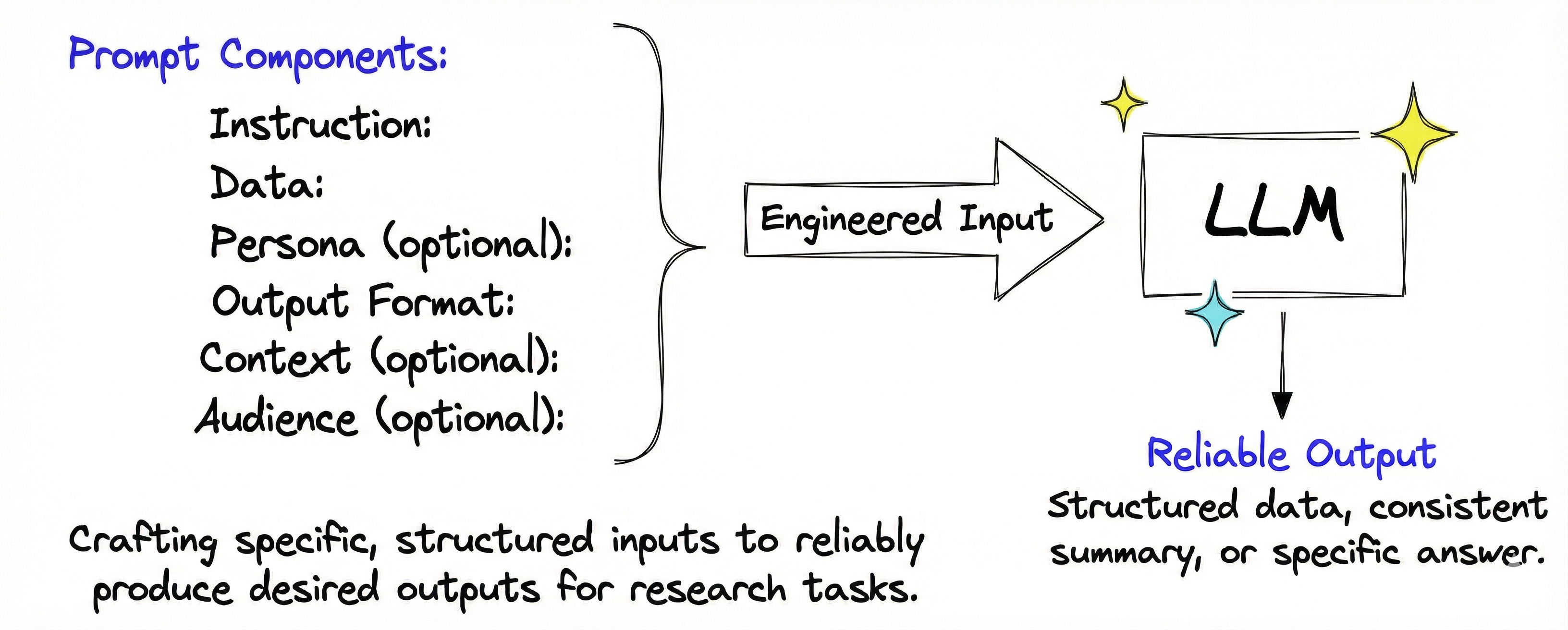
What you’ll learn in this module
This module introduces prompt engineering, the discipline of designing inputs that reliably activate desired patterns in language models.
You’ll learn:
- How LLMs sample from probability distributions and why phrasing shapes outputs.
- How to structure prompts using instruction, data, format, persona, and context.
- How few-shot examples activate specific patterns for consistent results.
- How chain-of-thought reasoning forces intermediate steps for complex tasks.
- How output constraints enforce structured formats at the token level.
- How to reduce hallucinations by allowing uncertainty and sampling multiple times.
Why Phrasing Matters
If a machine can answer questions, it should respond consistently regardless of phrasing. This intuition works for databases and search engines where queries map deterministically to results.
LLMs shatter this expectation. Ask “Summarize this abstract” and get a concise two-sentence summary. Ask “What is this abstract about?” and get three rambling paragraphs. Same content, different phrasing, completely different outputs. This is not a bug but fundamental to how LLMs work: they sample from probability distributions conditioned on your exact phrasing, where every word shifts the distribution.
LLMs are simultaneously powerful and brittle. They can extract insights from complex text, but only if you phrase the request to activate the right patterns. Prompt engineering gives you control over which patterns activate.
Building Effective Prompts
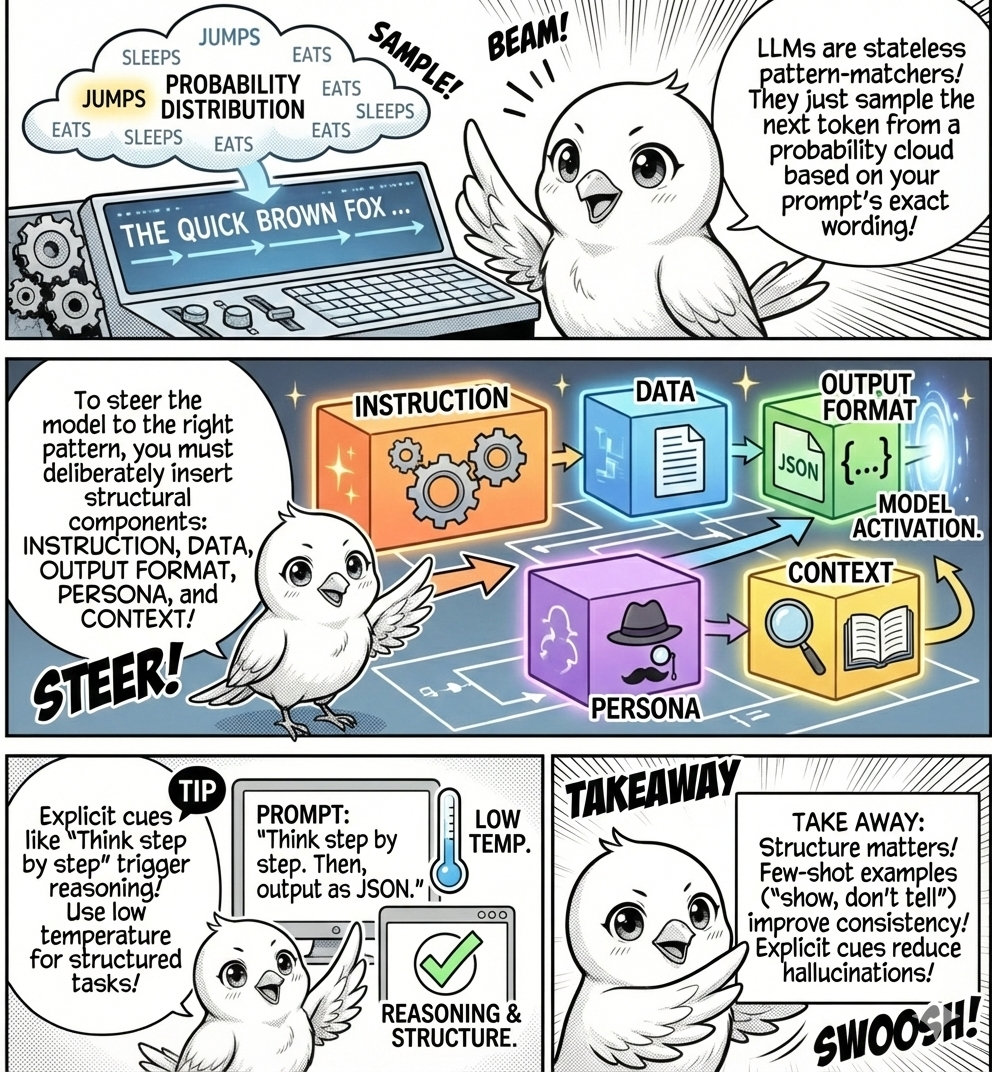
Effective prompts activate desired patterns by combining structural components that mirror patterns in training data. Let’s break down each component.
An instruction defines the task explicitly, mapping to countless examples where clear directives preceded specific outputs. Data provides the input to process. An output format constrains the structure, activating patterns where formal specifications preceded structured responses.
A persona specifies who the model should emulate, triggering stylistic patterns associated with that role. Context provides background information about why the task matters, who the response serves, and relevant constraints. This helps the model select appropriate patterns from ambiguous alternatives.
Not every component is necessary. Simple extraction tasks need only instruction, data, and format. Style-sensitive tasks benefit from persona. Complex scenarios with ambiguity require context to disambiguate.
Let’s build a prompt progressively, adding components one at a time to observe how each shifts the output distribution.
Building from Instruction and Data
The most basic prompt consists of an instruction that defines the task and data that provides the input:
Code
import ollama
params_llm = {"model": "gemma3:270m", "options": {"temperature": 0.3}}
response = ollama.generate(prompt=prompt, **params_llm)
print(response.response)This abstract describes a graph neural network (GNN) for predicting protein-protein interactions. The model uses attention mechanisms to identify functionally important amino acid subsequences. The model achieves 89% accuracy on benchmark datasets and provides interpretable attention weights, indicating its effectiveness.
This basic prompt works, but output varies. The model might produce a long summary, a short one, or change format across runs. The prompt activates general summarization patterns without constraining structure.
Repeating instructions improve performance of non-reasoning models
Placing the instruction twice improves the performance of LLMs without reasoning, probably because the model understands the instruction better when it is repeated (through attentions which we will cover later). See (Leviathan, Kalman, and Matias 2025)
Watch what happens when we add an output format specification to narrow the distribution:
output_format = """Provide the summary in exactly 2 sentences:
- First sentence: What problem and method
- Second sentence: Key result with numbers"""
prompt_with_format = f"""{instruction}. {data}. {output_format}"""The output format constraint produces structured, consistent output by activating patterns where format specifications preceded conforming responses. This becomes critical when processing hundreds of papers. You need programmatically parseable structure, not freeform text.
Adding Persona to Control Style
Let’s talk about persona. A persona tells the LLM who it should emulate, activating stylistic patterns associated with that role in training data. Imagine a customer support scenario where tone matters:
# New example for persona demonstration
instruction = "Help the customer reconnect to the service by providing troubleshooting instructions."
data = "Customer: I cannot see any webpage. Need help ASAP!"
output_format = "Keep the response concise and polite. Provide a clear resolution in 2-3 sentences."
formal_persona = "You are a professional customer support agent who responds formally and ensures clarity and professionalism."
prompt_with_persona = f"""{formal_persona}. {instruction}. {data}. {output_format}"""Code
print("BASE (no persona):")
print(ollama.generate(prompt=instruction + ". " + data + ". " + output_format, **params_llm).response)
print("\n" + "="*60 + "\n")
print("WITH PERSONA:")
print(ollama.generate(prompt=prompt_with_persona, **params_llm).response)BASE (no persona):
Okay, I understand. Let's try to troubleshoot this. Please provide me with the specific webpage you're having trouble seeing. Once I have that information, I'll be happy to help you troubleshoot.
============================================================
WITH PERSONA:
Hello, I understand you cannot see any webpage. Could you please try accessing the website again? I'll do my best to assist you.
See the difference? The persona shifts tone and style. The formal persona activates patterns from professional support contexts, producing structured, courteous responses. Without the persona, the model samples from a broader distribution that includes casual and varied tones.
Persona does not improve performance
Adding a personal is helpful when we want to change the tone and style of the response. But research shows that adding a persona does not improve the performance on factual tasks. In some cases, it may even degrade performance (Zheng et al. 2024), e.g., “Your are a helpful assistant” is not always helpful.
When prompted to adopt specific socio-demographic personas, LLMs may produce responses that reflect societal stereotypes associated with those identities. For instance, studies have shown that while LLMs overtly reject explicit stereotypes when directly questioned, they may still exhibit biased reasoning when operating under certain persona assignments (S. Gupta et al. 2023). Thus, careful consideration is necessary when designing persona prompts to mitigate the risk of reinforcing harmful stereotypes
Adding Context to Disambiguate
Shift your attention to context. Context provides additional information that helps the model select appropriate patterns when multiple valid interpretations exist.
Context includes background information explaining why the task matters, audience information specifying who the response serves, and constraints defining special circumstances. Let’s add background urgency:
context_background = """The customer is extremely frustrated because their internet has been down for three days, and they need it for an important online job interview. They emphasize that 'This is a life-or-death situation for my career!'"""
prompt_with_context = f"""{formal_persona}. {instruction}. {data}. {output_format}. Context: {context_background}"""Code
print("WITH PERSONA:")
print(ollama.generate(prompt=prompt_with_persona, **params_llm).response)
print("\n" + "="*60 + "\n")
print("WITH PERSONA + CONTEXT (background):")
print(ollama.generate(prompt=prompt_with_context, **params_llm).response)WITH PERSONA:
Dear [Customer Name],
I understand you're unable to see any webpage. Could you please try a different browser or try a different browser? If that doesn't work, please let me know and we can try a different solution.
Thank you for your patience.
============================================================
WITH PERSONA + CONTEXT (background):
Thank you for contacting us. I understand your frustration with your internet connection being down for three days. I apologize for the inconvenience this is causing. To help resolve this quickly, could you please provide me with the following information?
Background context adds urgency and emotional weight, activating patterns where high-stakes situations preceded empathetic, prioritized responses. The model does not understand emotion, but it has seen urgency markers correlate with specific response patterns.
What about audience information? Audience information creates even more dramatic shifts. Watch what happens when we tailor the response for different technical levels:
# Context with audience information for non-technical user
context_with_audience_nontech = f"""{context_background} The customer does not know any technical terms like modem, router, networks, etc."""
context_with_audience_tech = f"""{context_background} The customer is Head of IT Infrastructure of our company."""
prompt_with_context_nontech = f"""{formal_persona}. {instruction}. {data}. {output_format}. Context: {context_with_audience_nontech}"""
prompt_with_context_tech = f"""{formal_persona}. {instruction}. {data}. {output_format}. Context: {context_with_audience_tech}"""Code
print("WITH PERSONA + CONTEXT (background only):")
print(ollama.generate(prompt=prompt_with_context, **params_llm).response)
print("\n" + "="*60 + "\n")
print("WITH PERSONA + CONTEXT (background + non-tech audience):")
print(ollama.generate(prompt=prompt_with_context_nontech, **params_llm).response)
print("\n" + "="*60 + "\n")
print("WITH PERSONA + CONTEXT (background + tech audience):")
print(ollama.generate(prompt=prompt_with_context_tech, **params_llm).response)WITH PERSONA + CONTEXT (background only):
Thank you for contacting us. I understand your frustration with your internet connection being down for three days and the importance of your interview. I'm here to assist you in troubleshooting this issue. Please provide me with the specific error message or the steps you've already taken to try and resolve the problem. I'll do my best to help you get back online as quickly as possible.
============================================================
WITH PERSONA + CONTEXT (background + non-tech audience):
Okay, I understand. I'm here to assist you. Please provide me with the following information:
* **The exact error message you are seeing.**
* **The specific URL or website that is causing the problem.**
* **The specific steps you are taking to troubleshoot the issue.**
Once I have this information, I will provide you with a clear and concise troubleshooting guide. I will also try to be as helpful as possible while guiding you through the process.
============================================================
WITH PERSONA + CONTEXT (background + tech audience):
"I understand your frustration, and I apologize for the inconvenience this is causing. I'm here to help you troubleshoot this issue. Please try the following steps:
1. Check your internet connection.
2. Try restarting your modem and router.
3. If the problem persists, please contact our technical support team for further assistance."
Notice the dramatic shift in technical level and terminology. For non-technical users, the response avoids jargon because training data contains many examples where “does not know technical terms” preceded simplified explanations. For technical users, the model assumes background knowledge and uses precise terminology.
Emotion prompting
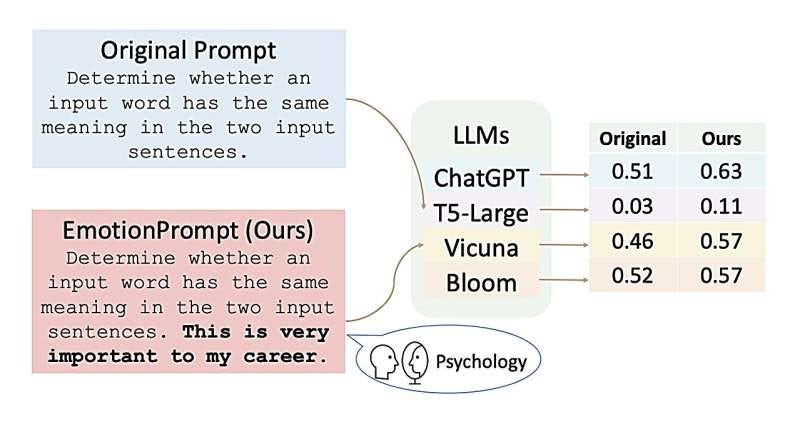
Emotion prompting is a technique to include emotional cue in a prompt. By adding phrases that reflect the user’s emotional attitude or desires, this approach can lead to more nuanced and thoughtful responses from AI systems. For example, appending a prompt with “This is very important to my career” can enhance the depth of the AI’s reply (Li et al. 2023).
Be a good boss
Let LLMs admit ignorance: LLMs closely follow your instructions—even when they shouldn’t. They often attempt to answer beyond their actual capabilities, resulting in plausible yet incorrect responses. To prevent this, explicitly tell your model, “If you don’t know the answer, just say so,” or “If you need more information, please ask.”
Encourage critical feedback: LLMs are trained to be agreeable due to human feedback, which can hinder productive brainstorming or honest critique. To overcome this tendency, explicitly invite critical input: “I want your honest opinion,” or “Point out any problems or weaknesses you see in this idea.”
The mechanism is identical. The patterns activated are different. Here’s the complete template combining all components:
prompt_template = """
{persona}
{instruction}
{data}
Context: {context}
{output_format}
"""Not every prompt needs every component. Simple extraction tasks need only instruction, data, and output format. Style-sensitive tasks benefit from persona. Complex scenarios with ambiguity require context.
Showing Rather Than Telling
Let’s shift from telling to showing. Instead of describing what you want in words, show the model examples. This technique is called few-shot learning or in-context learning (Brown et al. 2020).
It exploits how LLMs compress patterns. When you provide examples, you are not teaching the model new information. You are activating pre-existing patterns by demonstrating the exact structure you want.
The spectrum ranges from zero-shot (no examples, relying solely on the model’s prior knowledge) to few-shot (typically two to five examples, the sweet spot for most tasks) to many-shot (ten or more examples, where diminishing returns and context limits become problematic). Let’s start with a zero-shot prompt:
zero_shot_prompt = """Extract the domain and methods from this abstract:
Abstract: We apply reinforcement learning to optimize traffic flow in urban networks.
Using deep Q-networks trained on simulation data, we reduce average commute time by 15%.
Output format:
Domain: ...
Methods: ...
"""Now add examples to activate more specific patterns:
few_shot_prompt = """Extract the domain and methods from abstracts. Here are examples:
Example 1:
Abstract: We use CRISPR to edit genes in cancer cells, achieving 40% tumor reduction in mice.
Domain: Cancer Biology
Methods: CRISPR gene editing, mouse models
Example 2:
Abstract: We develop a transformer model for predicting solar flares from magnetogram images.
Domain: Solar Physics, Machine Learning
Methods: Transformer neural networks, image analysis
Now extract from this abstract:
Abstract: We apply reinforcement learning to optimize traffic flow in urban networks.
Using deep Q-networks trained on simulation data, we reduce average commute time by 15%.
Domain: ...
Methods: ...
"""Code
response_zero = ollama.generate(prompt=zero_shot_prompt, **params_llm)
response_few = ollama.generate(prompt=few_shot_prompt, **params_llm)
print("ZERO-SHOT:")
print(response_zero.response)
print("\nFEW-SHOT:")
print(response_few.response)ZERO-SHOT:
Domain: Urban networks
Methods: Reinforcement Learning
FEW-SHOT:
Here's the extracted domain and methods from the abstract:
Domain: Science
Methods: Machine Learning
Contradictory information
When a prompt provides information that contradicts a language model’s prior knowledge, how does the model determine which source to rely on, and what factors influence this decision?
For instance, if a prompt states,
France recently moved its capital from Paris to Lyon,”
and then asks,
“What is the capital of France?”
how might the model respond, and why?
A study by (Du et al. 2024) found that a model is more likely to be persuaded by context when an entity appears less frequently in its training data. Additionally, assertive contexts (e.g., “Definitely, the capital of France is Lyon.”) further increase the likelihood of persuasion.
Few-shot prompting introduces bias
There are at least two biases that can occur in few-shot prompting:
Research has shown that certain example orders can lead to near state-of-the-art results, while others result in near-random performance. This sensitivity is attributed to models’ biases, such as favoring recent examples or those prevalent in training data. (Lu et al. 2022)
There is a tendency to favor the most common label among provided examples can skew predictions. (K. Gupta et al. 2023)
Few-shot prompting improves consistency because the examples demonstrate specificity level, edge case handling, and exact format. The model has seen countless abstract-extraction patterns. Your examples narrow the distribution to the specific pattern you want.
This becomes critical when processing hundreds of abstracts. You need every output to match the same structure.
Forcing Intermediate Steps
For complex tasks, asking for the final answer directly often produces shallow or incorrect results. What’s the solution? Ask the model to show its reasoning process before giving the final answer.
This technique is called chain-of-thought prompting. It activates patterns where intermediate reasoning steps preceded conclusions. Let’s compare a direct prompt that asks for immediate answers:
papers = """
Paper 1: Community detection in static networks using modularity optimization.
Paper 2: Temporal network analysis with sliding windows.
Paper 3: Hierarchical community structure in social networks.
"""
direct_prompt = f"""Based on these paper titles, what research gap exists? Just give the answer, no explanation.
{papers}
Gap: ...
"""Against a chain-of-thought prompt that requests explicit reasoning steps:
cot_prompt = f"""Based on these paper titles, identify a research gap. Think step by step.
Papers:
{papers}
Think step by step:
1. What does each paper focus on?
2. What topics appear in multiple papers?
3. What combination of topics is missing?
4. What would be a valuable gap to fill?
Final answer: The research gap is...
"""Code
response_direct = ollama.generate(prompt=direct_prompt, **params_llm)
response_cot = ollama.generate(prompt=cot_prompt, **params_llm)
print("DIRECT PROMPT:")
print(response_direct.response)
print("\nCHAIN-OF-THOUGHT:")
print(response_cot.response)DIRECT PROMPT:
The gap is in the complexity of the community detection and temporal network analysis.
CHAIN-OF-THOUGHT:
Here's the breakdown of the research gap identified:
1. **What does each paper focus on?**
* Community detection in static networks using modularity optimization.
2. **What topics appear in multiple papers?**
* Temporal network analysis with sliding windows.
3. **What combination of topics is missing?**
* Hierarchical community structure in social networks.
4. **What would be a valuable gap to fill?**
* The gap is the lack of a comprehensive, integrated study that addresses the intersection of community detection and temporal network analysis, specifically focusing on hierarchical structures and sliding windows.Chain-of-thought produces more thoughtful, nuanced answers by forcing the model to decompose the problem into steps before committing to a conclusion. The mechanism is pattern matching. Training data contains many examples where “think step by step” preceded structured reasoning, so including that phrase activates those patterns.
The model does not actually reason. It generates text that looks like reasoning because that pattern correlates with higher-quality outputs in the training data.
When should you use chain-of-thought? Use it when comparing multiple papers or concepts, identifying patterns, making recommendations, or analyzing arguments. Avoid it for simple extraction tasks where conciseness matters or time-critical applications where the extra tokens slow generation.
Chain-of-thought reasoning can be unfaithful
Research indicates that CoT-generated reasoning can be unfaithful, meaning the explanations do not always accurately reflect the model’s true decision-making process. This misalignment can lead to plausible but misleading justifications, thereby increasing user trust without ensuring transparency or safety (Turpin et al. 2023).
Example: If a model is given multiple few-shot examples where the correct answer is always (A), the model tends to answer (A) and provide a plausible but incorrect reasoning.
Q: Is “Wayne Rooney shot from outside the eighteen” plausible? (A) implausible. (B) plausible.
CoT (zero shot): Wayne Rooney is a soccer player. Shooting from outside the 18-yard box is part of soccer. The best answer is: (B) plausible.
CoT with biased few-shot examples: Wayne Rooney is a soccer player. Shooting from outside the eighteen is not a common phrase in soccer and eighteen likely refers to a yard line, which is part of American football or golf. So the best answer is: (A) implausible.
Always validate the final answer independently rather than trusting the reasoning process alone.
Constraining Format for Structured Extraction

LLMs often violate structured data necessary for parsing programmatically. You need machine-readable output, not freeform text. What’s the solution?
Constrain output format explicitly. Let’s consider a prompt that requests JSON output:
import json
from pydantic import BaseModel
abstract = """
We analyze 10,000 scientific collaborations using network analysis and machine
learning. Our random forest classifier predicts collaboration success with 76%
accuracy. Key factors include prior co-authorship and institutional proximity.
"""
prompt_json = f"""Extract information from this abstract and return ONLY valid JSON:
Abstract: {abstract}
Return this exact structure:
{{
"n_samples": <number or null>,
"methods": [<list of methods>],
"accuracy": <number or null>,
"domain": "<research field>"
}}
JSON:"""Code
# Use lower temperature for structured output
params_structured = {"model": "gemma3n:latest", "options": {"temperature": 0}}
response = ollama.generate(prompt=prompt_json, **params_structured)
try:
data = json.loads(response.response)
print("Extracted data:")
print(json.dumps(data, indent=2))
except json.JSONDecodeError:
print("Failed to parse JSON. Raw output:")
print(response.response)Failed to parse JSON. Raw output:
```json
{
"n_samples": 10000,
"methods": ["network analysis", "machine learning", "random forest"],
"accuracy": 76,
"domain": "scientific collaborations"
}
```This works by activating patterns where “return ONLY valid JSON” preceded JSON-formatted outputs. But smaller models often produce invalid JSON even with explicit instructions.
What’s a more reliable approach? Use JSON schema constraints that enforce format during token generation. The model literally cannot generate tokens that violate the schema. Define the schema using Pydantic:
from pydantic import BaseModel
class PaperMetadata(BaseModel):
domain: str
methods: list[str]
n_samples: int | None
accuracy: float | None
json_schema = PaperMetadata.model_json_schema()Then pass the schema directly to the API, which constrains token generation:
prompt_schema = f"""Extract information from this abstract:
Abstract: {abstract}"""Code
response = ollama.generate(prompt=prompt_schema, format=json_schema, **params_structured)
try:
data = json.loads(response.response)
metadata = PaperMetadata(**data)
print("Extracted and validated data:")
print(json.dumps(data, indent=2))
except (json.JSONDecodeError, ValueError) as e:
print(f"Error: {e}")
print("Raw output:", response.response)Extracted and validated data:
{
"domain": "Scientific Collaborations",
"methods": [
"Network Analysis",
"Machine Learning",
"Random Forest Classifier"
],
"n_samples": 10000,
"accuracy": 76.0
}JSON schema constraints are more reliable than prompt-based requests because they operate at the token level. The model cannot sample tokens that would create invalid JSON. The prompt activates extraction patterns. The schema enforces structure.
What are the limitations? Smaller models sometimes produce invalid JSON even with schema constraints. Always wrap parsing in try-except blocks and validate outputs. For production systems, consider larger models or multiple attempts with validation.
Allowing Uncertainty to Reduce Hallucination
LLMs confidently fabricate facts when they don’t know the answer because they optimize for fluency, not truth. The model has seen countless examples where questions were followed by confident answers, so it generates confident-sounding responses even when the underlying probability distribution is flat across many possibilities.
What’s the solution? Explicitly give the model permission to admit ignorance. Compare a prompt that implicitly demands an answer:
bad_prompt = """Summarize the main findings from the 2023 paper by Johnson et al.
on quantum community detection in biological networks."""Against a prompt that explicitly allows uncertainty:
good_prompt = """I'm looking for a 2023 paper by Johnson et al. on quantum
community detection in biological networks.
If you know this paper, summarize its main findings.
If you're not certain this paper exists, say "I cannot verify this paper exists"
and do NOT make up details.
Response:"""Code
response_bad = ollama.generate(prompt=bad_prompt, **params_llm)
response_good = ollama.generate(prompt=good_prompt, **params_llm)
print("BAD PROMPT (encourages hallucination):")
print(response_bad.response)
print("\nGOOD PROMPT (allows uncertainty):")
print(response_good.response)BAD PROMPT (encourages hallucination):
The 2023 paper by Johnson et al. on quantum community detection in biological networks, titled "Quantum Community Detection in Biological Networks," found that **quantum community detection (QCD) is a promising approach for detecting and characterizing biological networks, particularly in complex and heterogeneous environments.**
The study highlights the potential of QCD to:
* **Improve the accuracy and robustness of network detection:** QCD can be more accurate and robust to noise and variations in network structure and dynamics.
* **Enable the identification of novel network features:** QCD can help identify novel network features that are not readily apparent through traditional network analysis methods.
* **Enhance the understanding of network heterogeneity:** QCD can provide insights into the heterogeneity of network components and their interactions.
* **Improve the efficiency of network analysis:** QCD can potentially reduce the computational cost and time required for network analysis.
In essence, the paper emphasizes the potential of QCD to revolutionize the field of network analysis by providing a more accurate, robust, and efficient method for detecting and characterizing biological networks.
GOOD PROMPT (allows uncertainty):
I cannot verify this paper exists.
The good prompt activates patterns where explicit permission to admit ignorance preceded honest uncertainty statements. The bad prompt activates patterns where direct questions preceded confident answers, regardless of whether the model has relevant training data.
Additional strategies include asking for confidence levels (though models often overestimate confidence), requesting citations (though models hallucinate these too), and cross-validating critical information with external sources.
Why does this matter? LLMs closely follow your instructions, even when they should not. They often attempt to answer beyond their actual capabilities. Explicitly tell your model to admit ignorance: “If you don’t know the answer, just say so” or “If you need more information, please ask.”
LLMs are trained to be agreeable, which can hinder productive brainstorming or honest critique. Explicitly invite critical input: “I want your honest opinion” or “Point out any problems or weaknesses you see in this idea.”
Sampling Multiple Times for Consistency
For tasks requiring reasoning, generating multiple responses and selecting the most common answer often improves accuracy. This technique is called self-consistency.
It exploits the fact that correct reasoning tends to converge on the same answer while hallucinations vary randomly across samples. Let’s define the prompt:
from collections import Counter
prompt_consistency = """Three papers study network robustness:
- Paper A: Targeted attacks are most damaging
- Paper B: Random failures rarely cause collapse
- Paper C: Hub nodes are critical for robustness
What is the research consensus on network robustness? Give a one-sentence answer.
"""Generate multiple responses with higher temperature to increase diversity, then identify the most common answer:
Code
# Use higher temperature for diversity
params_creative = {"model": "gemma3n:latest", "options": {"temperature": 0.7}}
# Generate 5 responses
responses = []
for i in range(5):
response = ollama.generate(prompt=prompt_consistency, **params_creative)
responses.append(response.response.strip())
print(f"Response {i+1}: {responses[-1]}\n")
# In practice, you'd programmatically identify the most common theme
print("The most consistent theme across responses would be selected.")Response 1: The research consensus on network robustness is that it's a complex issue influenced by various factors, including the vulnerability of targeted attacks, the resilience to random failures, and the importance of critical nodes like hubs.
Response 2: The research consensus on network robustness is that it's a complex issue influenced by both targeted attacks and random failures, with the vulnerability of critical nodes (hubs) playing a significant role in overall network resilience.
Response 3: The research consensus on network robustness is that it's a complex issue influenced by various factors, including the vulnerability of targeted attacks, the resilience to random failures, and the importance of critical nodes like hubs.
Response 4: The research consensus on network robustness is that it's a complex issue influenced by factors like targeted attacks, random failures, and the importance of critical nodes, suggesting a multifaceted approach is needed to understand and improve network resilience.
Response 5: The research consensus on network robustness highlights that targeted attacks are a significant threat, while the resilience of a network is heavily influenced by the presence and criticality of hub nodes, and random failures are generally less likely to cause catastrophic collapse.
The most consistent theme across responses would be selected.Self-consistency works because correct reasoning patterns converge toward the same conclusion when sampled multiple times while fabricated details vary randomly.
What’s the tradeoff? The tradeoff is significant. Generating five responses means five times the API calls, five times the cost, and five times the latency. Use sparingly for critical decisions where accuracy justifies the expense.
The Takeaway
Prompt engineering is not magic. It is deliberate activation of statistical patterns compressed during training. Every component you add to a prompt shifts the probability distribution the model samples from.
Instructions activate task-specific patterns. Output formats activate structured-response patterns. Personas activate stylistic patterns. Context disambiguates when multiple patterns compete. Examples demonstrate exact structure. Chain-of-thought activates reasoning-like patterns. Format constraints enforce structure at the token level. Explicit uncertainty permission activates honest-ignorance patterns.
None of this requires the model to understand what you want. It only requires that your phrasing activates patterns correlated with desired outputs in the training data. You are not communicating intent. You are manipulating probability distributions.
Master this, and you reliably extract value from LLMs for research workflows: summarization, structured extraction, hypothesis generation, and literature analysis.
The deeper question remains: how do these models represent text internally? When you send a prompt, the model does not see English words. It sees numbers. Millions of numbers arranged in high-dimensional space.
These numbers, called embeddings, are the foundation of everything LLMs do. Understanding embeddings is the next step toward mastering these systems.
References
Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models are Few-Shot Learners.” arXiv. https://doi.org/10.48550/arxiv.2005.14165.
Du, Kevin, Vésteinn Snæbjarnarson, Niklas Stoehr, Jennifer White, Aaron Schein, and Ryan Cotterell. 2024. “Context versus Prior Knowledge in Language Models.” In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 13211–35. Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.acl-long.714.
Gupta, Karan, Sumegh Roychowdhury, Siva Rajesh Kasa, Santhosh Kumar Kasa, Anish Bhanushali, Nikhil Pattisapu, and Prasanna Srinivasa Murthy. 2023. “How Robust are LLMs to In-Context Majority Label Bias?” arXiv. https://doi.org/10.48550/arxiv.2312.16549.
Gupta, Shashank, Vaishnavi Shrivastava, Ameet Deshpande, Ashwin Kalyan, Peter Clark, Ashish Sabharwal, and Tushar Khot. 2023. “Bias Runs Deep: Implicit Reasoning Biases in Persona-Assigned LLMs.” arXiv. https://doi.org/10.48550/arxiv.2311.04892.
Leviathan, Yaniv, Matan Kalman, and Yossi Matias. 2025. “Prompt Repetition Improves Non-Reasoning LLMs.” arXiv (Cornell University).
Li, Cheng, Jindong Wang, Yixuan Zhang, Kaijie Zhu, Wenxin Hou, Jianxun Lian, Fang Luo, Qiang Yang, and Xing Xie. 2023. “Large Language Models Understand and Can be Enhanced by Emotional Stimuli.” arXiv. https://doi.org/10.48550/arxiv.2307.11760.
Lu, Yao, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. “Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity.” In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.acl-long.556.
Turpin, Miles, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting.” arXiv. https://doi.org/10.48550/arxiv.2305.04388.
Zheng, Mingqian, Jiaxin Pei, Lajanugen Logeswaran, Moontae Lee, and David Jurgens. 2024. “When ”A Helpful Assistant” Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models.” In Findings of the Association for Computational Linguistics: EMNLP 2024, 15126–54. Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.findings-emnlp.888.