from sentence_transformers import SentenceTransformer, util
# Load a pre-trained model
model = SentenceTransformer('all-MiniLM-L6-v2')
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin.",
"Two men pushed carts through the woods.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"Someone in a gorilla costume is playing a set of drums."
]
# Encode all sentences into 384-dimensional vectors
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
query = "A man is eating pasta."
query_embedding = model.encode(query, convert_to_tensor=True)
# Compute cosine similarities
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=3)
print(f"Query: {query}")
print("\nTop 3 most similar sentences:")
for hit in hits[0]:
print(f"{corpus[hit['corpus_id']]} (Score: {hit['score']:.4f})")Sentence Transformers
What you’ll learn in this module
This module introduces Sentence Transformers, which collapse BERT’s token matrices into single vectors for fast semantic search.
You’ll learn:
- How Siamese Networks use shared weights to embed sentences in a common vector space.
- The role of pooling strategies (mean, max, CLS-token) in collapsing token matrices into sentence embeddings.
- How to perform semantic search and clustering with pre-trained models.
- The speed-accuracy trade-offs across different model sizes and architectures.
- Where sentence embeddings break down (context collapse, word order sensitivity, domain shift).
BERT gives you a vector for every token in a sentence. If you want to compare two sentences, you’re stuck comparing two messy matrices of varying sizes.
The naive approach is to average all token vectors. But this throws away positional information and treats every word equally. The word “not” in “not good” should drastically change the sentence embedding, but simple averaging dilutes its impact.
What’s the Solution?
Sentence-BERT (SBERT) solves this by training a Siamese Network. The same BERT model processes two sentences independently, producing their respective token matrices. We then apply pooling (mean, max, or CLS-token extraction) to collapse each matrix into a single vector.
The training objective is contrastive. If the sentences are semantically similar (paraphrases), their vectors should be close in Euclidean or cosine space. If they’re unrelated, their vectors should be distant.
Think of it like creating a library catalog. Instead of storing every word on every page, you compress each book into a single Dewey Decimal number. Books on similar topics get similar numbers, enabling efficient retrieval. The compression loses fine-grained detail, but gains search speed.
Why Does Weight Sharing Matter?
The mathematical trick is the Siamese architecture. Weight sharing ensures both sentences are embedded into the same vector space using identical transformations.
This makes the distance between vectors meaningful. Similar sentences cluster together, dissimilar ones push apart.
How to Use Sentence Transformers
Let’s see how to use Sentence Transformers in practice. We’ll start with semantic search, then move to clustering.
Basic Semantic Search
Here’s how to encode sentences and find the most similar matches:
The model correctly identifies “eating pasta” is semantically closest to “eating food” and “eating bread”, even though the exact words don’t match. This is semantic search: matching by meaning, not keywords.
Clustering Documents
You can also cluster documents by their semantic content:
from sentence_transformers import SentenceTransformer
from sklearn.cluster import KMeans
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = [
"Python is a programming language",
"Java is used for software development",
"The cat sat on the mat",
"Dogs are loyal animals",
"Machine learning is a subset of AI",
"Neural networks mimic the brain",
]
embeddings = model.encode(sentences)
# Cluster into 2 groups
num_clusters = 2
clustering_model = KMeans(n_clusters=num_clusters, random_state=42)
clustering_model.fit(embeddings)
cluster_assignment = clustering_model.labels_
clustered_sentences = {}
for sentence_id, cluster_id in enumerate(cluster_assignment):
if cluster_id not in clustered_sentences:
clustered_sentences[cluster_id] = []
clustered_sentences[cluster_id].append(sentences[sentence_id])
for cluster_id, cluster_sentences in clustered_sentences.items():
print(f"\nCluster {cluster_id + 1}:")
for sentence in cluster_sentences:
print(f" - {sentence}")The model separates technical/programming sentences from animal-related sentences without any labeled data. This is unsupervised semantic clustering.
Which Model Should You Use?
Different Sentence Transformer models optimize for different trade-offs. The all-MiniLM-L6-v2 model is fast and lightweight (384 dimensions), good for most applications. The all-mpnet-base-v2 model offers higher quality (768 dimensions), slower but more accurate.
The multi-qa-mpnet-base-dot-v1 model is optimized for question-answering and retrieval tasks. The paraphrase-multilingual-mpnet-base-v2 model supports 50+ languages.
What should drive your choice? Speed vs. accuracy, monolingual vs. multilingual, general-purpose vs. domain-specific. Pick the model that matches your constraints.
How Does the Architecture Work?
Let’s talk about the Siamese Network architecture. Here’s the visual:
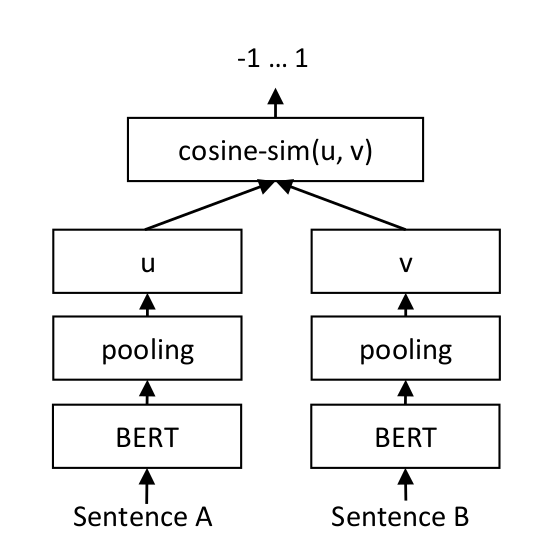
Both sentences pass through the same BERT model (shared weights). This ensures they’re embedded into a common vector space. The pooling layer then collapses each token matrix into a single vector.
During training, the loss function pushes similar sentence pairs together and dissimilar pairs apart. This is contrastive learning: positive pairs attract, negative pairs repel.
What Pooling Strategy Should You Use?
You have three main choices. Mean pooling averages all token vectors (most common). Max pooling takes the element-wise maximum across tokens. CLS-token uses the [CLS] token’s final hidden state (BERT’s built-in sentence representation).
Mean pooling generally works best. It captures information from all tokens while being robust to varying sentence lengths.
Where Does This Break?
Static compression is a limitation. A sentence gets exactly one vector, regardless of context. “The bank” in “the river bank” and “the financial bank” might get similar embeddings if they share enough surrounding words. The model compresses meaning into a fixed point, losing nuance.
Word order sensitivity is another concern. “The dog bit the man” and “The man bit the dog” share the same words. If the model relies too heavily on lexical overlap (bag-of-words similarity), they’ll end up dangerously close in vector space.
Good models learn syntax, but they’re not perfect.
What about computational cost? Although retrieval is fast (dot products), encoding large corpora is expensive. Encoding 1 million sentences with a large model can take hours. Pre-compute and cache embeddings whenever possible.
Domain shift is a practical issue. Models trained on general text (Wikipedia, news) may perform poorly on specialized domains (medical, legal). Fine-tuning on domain-specific data helps, but requires labeled sentence pairs.
The Key Takeaway
Sentence Transformers collapse BERT’s token matrix into a single vector using Siamese Networks and contrastive learning. The result is fast semantic search: encode once, compare with dot products.
Choose your pooling strategy and model size based on speed-accuracy trade-offs. Remember that compression always loses information.