This module explores a surprising empirical discovery about learned representations across different models.
You’ll learn:
What the Strong Platonic Representation Hypothesis claims and why all sufficiently large embedding models may learn nearly identical geometric structures.
How to discover universal latent structure hidden within fundamentally incomparable embedding spaces.
The technique of unsupervised translation (vec2vec) that aligns embedding spaces without paired data using cycle consistency.
Practical consequences for representation learning and the security of vector databases.
The Puzzle of Incomparable Spaces
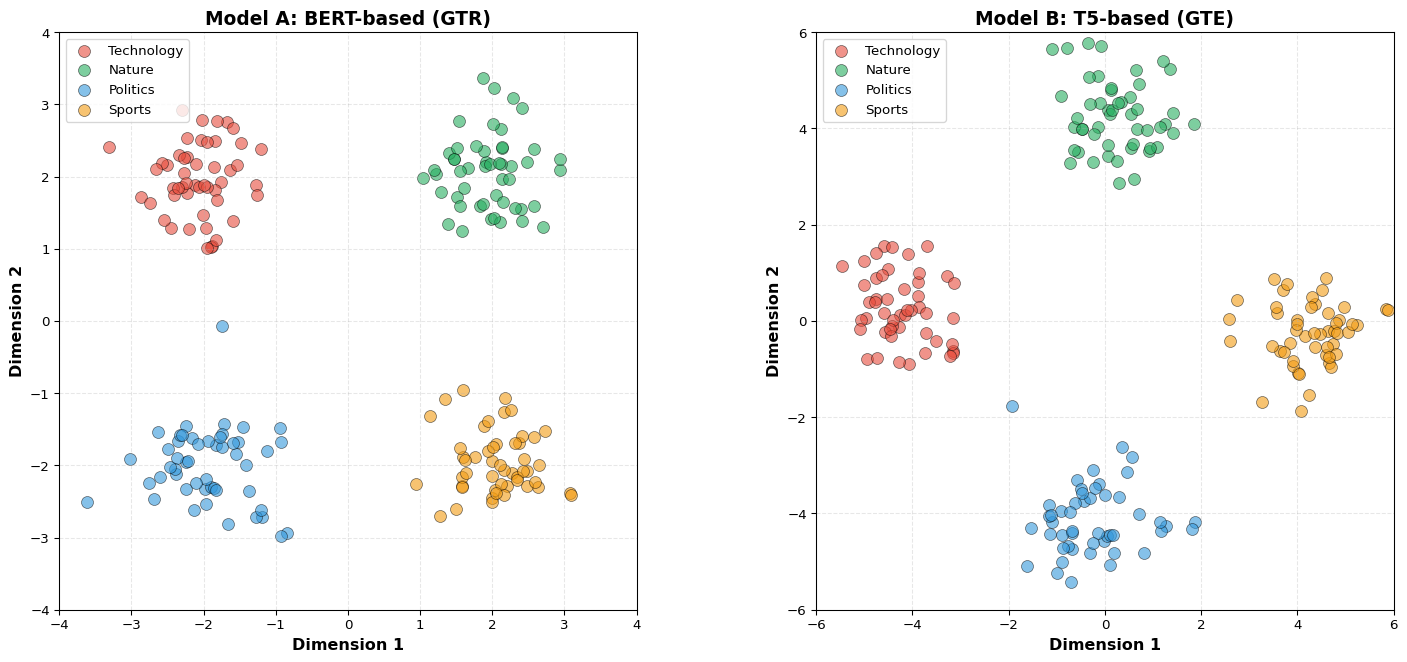
Let’s start with a practical question that reveals something profound. Suppose you have two different text embedding models, each trained independently on different datasets, using different architectures. Model A might be based on BERT (bidirectional transformer) while Model B might use T5 (encoder-decoder architecture), with different numbers of parameters, different training corpora (Wikipedia versus web crawl data), and different embedding dimensions (768-d versus 1024-d).
Are these two models learning the same thing? You might expect the answer to be “no, obviously not” given their different architectures, training data, and optimization procedures.
Figure 1: Two models trained independently produce fundamentally incomparable embedding spaces.
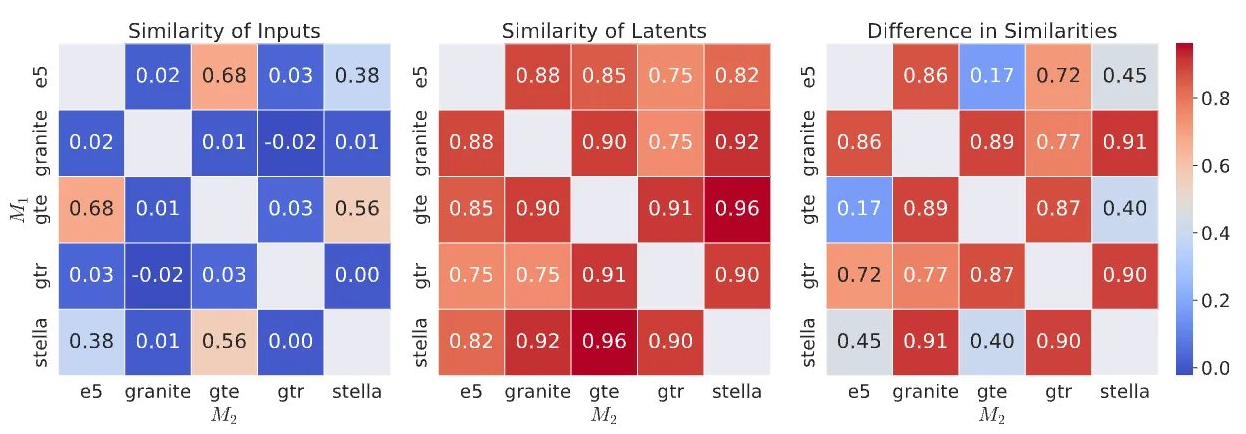
What do these two spaces have in common? At first glance, nothing. The coordinates are different, the distances are different, and computing the cosine similarity between two words in Model A versus Model B yields completely different numbers. The spaces appear fundamentally incomparable.
The Platonic Representation Hypothesis
Yet recent research suggests something remarkable. Despite these surface differences, the two models may have learned essentially the same underlying structure.
This conjecture is called the Platonic Representation Hypothesis. The hypothesis claims that all models of sufficient capacity, when trained on rich enough data, converge to the same latent representation of reality. The original hypothesis was introduced by Huh et al. (2024) in the context of vision models (Huh et al. 2024), who observed that different CNN architectures trained on ImageNet produced internal representations that aligned surprisingly well, discovering the same features (edges, textures, object parts) in the same hierarchical order without explicit programming.
Why would this happen? One explanation is that the structure isn’t in the model but in the world itself.
Visual recognition requires detecting edges (invariant properties of physical objects) and composing local features into global patterns (because objects have hierarchical part-whole structure). The optimal representation for vision isn’t arbitrary but constrained by the statistical structure of natural images. If you train many different models on the same underlying reality, they should all discover the same optimal representation. Think of the architecture and training procedure as different paths up a mountain that take different routes but converge toward the same peak.
The Strong Version: Text Can Be Translated
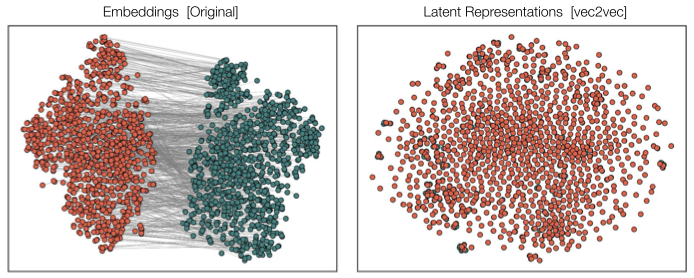
Jha et al. (2024) proposed a stronger, constructive version of this hypothesis for text embeddings. They introduced vec2vec, an unsupervised method for translating between embedding spaces (see project page).
Strong Platonic Representation Hypothesis: The universal latent structure of text representations not only exists, but can be learned and harnessed to translate representations from one space to another without any paired data or encoders.
This is a bold claim. It says you can take embeddings from Model A (which you don’t have access to), and translate them into the space of Model B, without ever seeing the same text encoded by both models. You don’t need parallel corpora. You don’t need paired examples. You only need unpaired samples from each space.
How is this possible? If the underlying semantic structure is truly universal, then the two embedding spaces are just different coordinate systems describing the same geometry. Think of Model A and Model B as two people describing the same city using different maps, one using latitude-longitude and the other using distance from landmarks. The coordinate systems differ, but the city’s structure (which streets connect, which neighborhoods are close) remains invariant.
Translation becomes a geometric alignment problem where you discover the rotation, scaling, and transformation that maps one coordinate system onto the other while preserving distances and relationships. The key insight is that semantic relationships (the parallel arrows representing analogies like man:king :: woman:queen) remain intact across all spaces. The coordinates change, but the geometry persists.
How Vec2Vec Works
The vec2vec method learns this translation through an adversarial game similar to CycleGAN (a technique from computer vision for image-to-image translation without paired examples).
The setup involves two generators and two discriminators. Generator G_{A \to B} attempts to translate embeddings from Model A’s space into Model B’s space. Generator G_{B \to A} does the reverse. Each generator is paired with a discriminator that tries to distinguish real embeddings from translated ones.
Three Key Losses
The training objective combines three losses. First, the adversarial loss encourages the generator to produce embeddings that look indistinguishable from real embeddings in the target space. If G_{A \to B} transforms an embedding from Model A, the discriminator D_B should not be able to tell it apart from genuine Model B embeddings.
Second, the cycle consistency loss ensures that if you translate from Space A to Space B and back to Space A, you should recover the original point. Mathematically, G_{B \to A}(G_{A \to B}(x)) \approx x. This prevents the model from learning arbitrary transformations that destroy information.
Third, the identity loss encourages the translation to preserve structure when no translation is needed. If you feed an embedding that already belongs to the target space, the generator should leave it mostly unchanged.
Why Does This Work?
The cycle consistency constraint forces the model to preserve the intrinsic geometry of the space. You cannot map every point to the same location (that would minimize adversarial loss but violate cycle consistency) or scramble relationships arbitrarily (that would break the round-trip property). The only way to satisfy all constraints simultaneously is to discover the true structural alignment between spaces.
Empirical Evidence
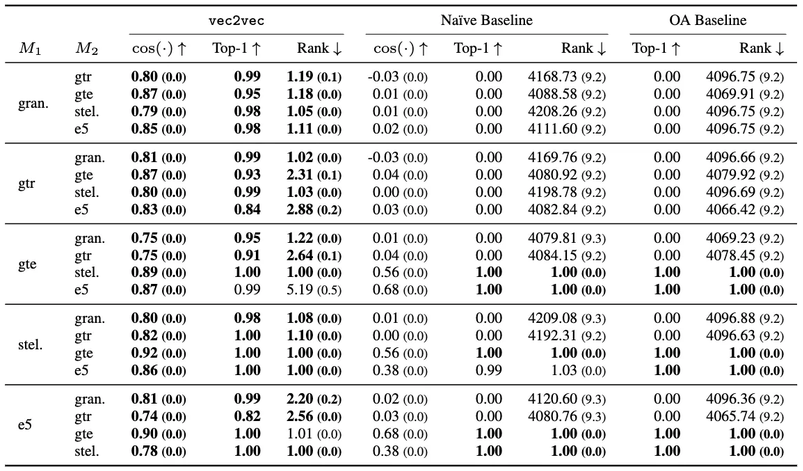
Jha et al. tested this by training vec2vec on multiple pairs of embedding models. They used models with different architectures (BERT-based versus T5-based), different training datasets, and different embedding dimensions.
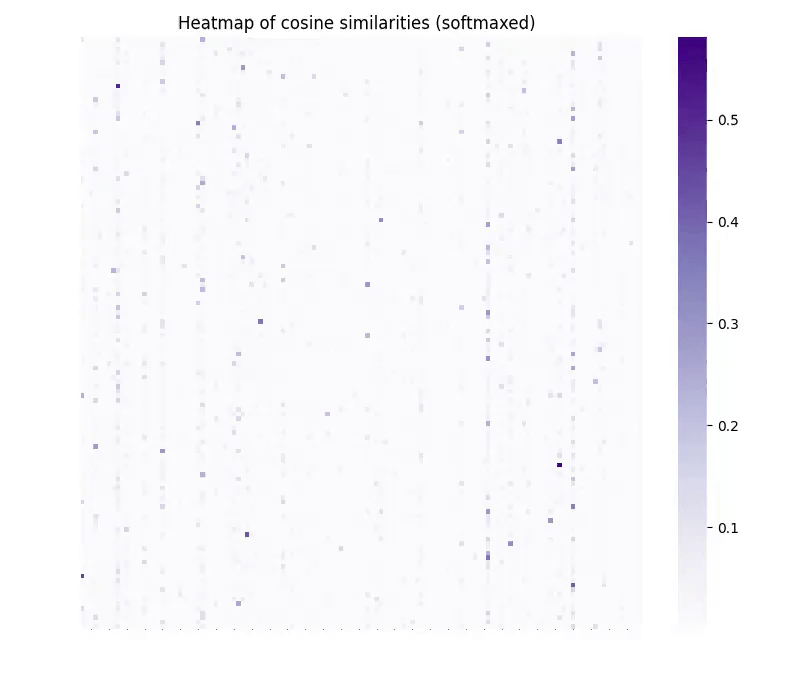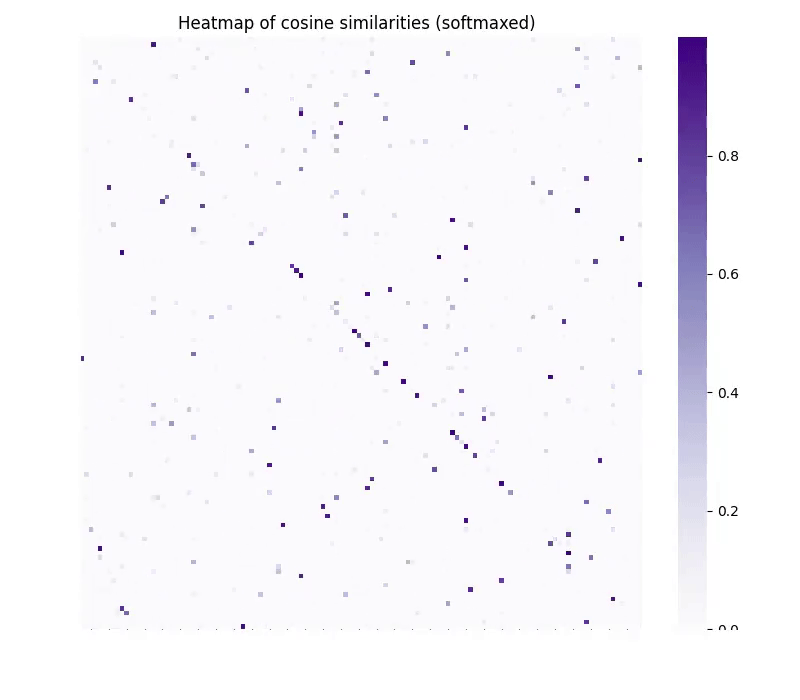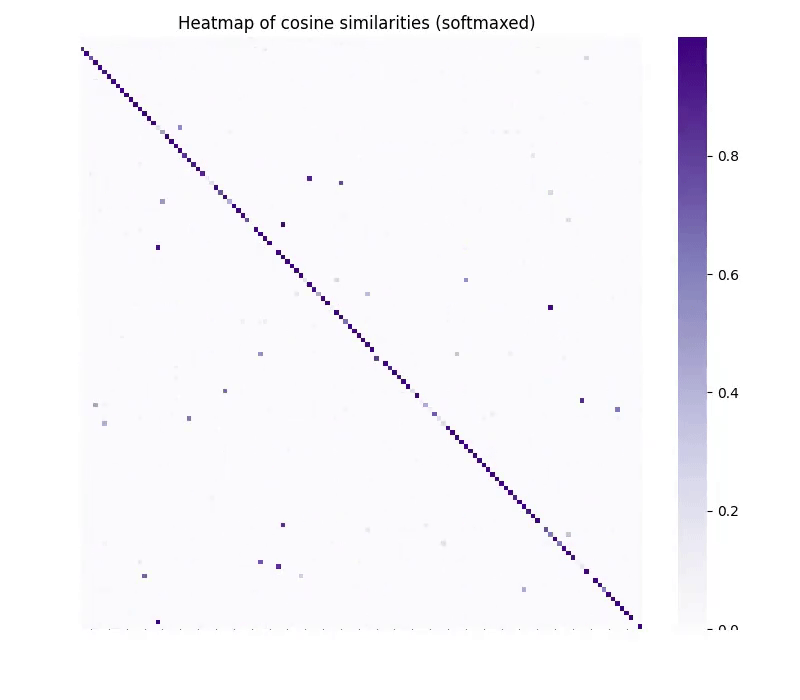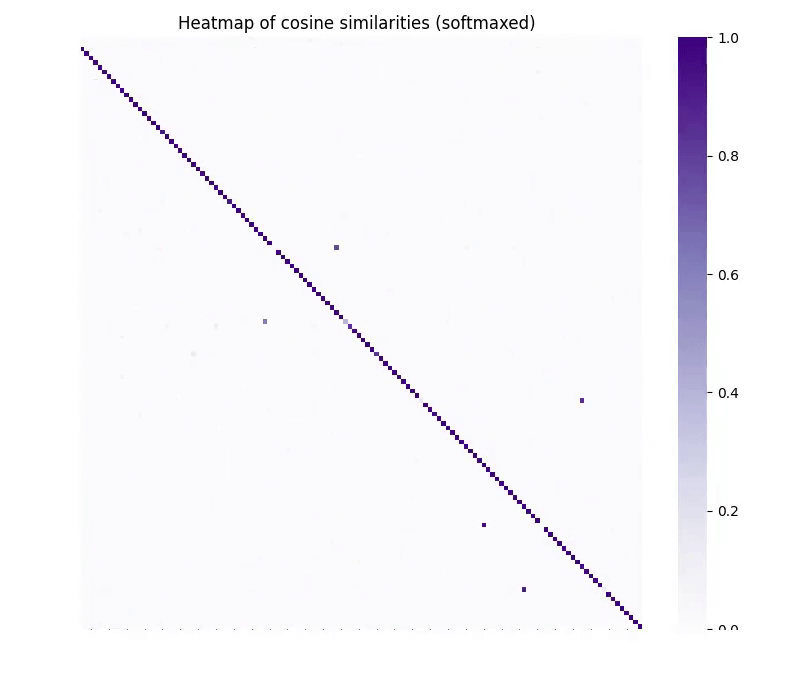
The results were striking. After training without any paired examples, vec2vec could translate embeddings between spaces while preserving their geometry. The cosine similarity between translated embeddings and ideal target embeddings reached above 0.9 in many cases.
What does this convergence tell us? Different embedding models, despite appearing incomparable on the surface, encode nearly identical semantic structures. The universal geometry exists, can be discovered, and can be exploited.
Generalization to Unseen Data
Perhaps the most surprising result is how well vec2vec generalizes. Train the translation model on embeddings from one dataset (say, Wikipedia articles), then test it on a completely different dataset (say, biomedical abstracts or code documentation), and the translation quality remains high. The model learned something general about the relationship between the two embedding spaces, not something specific to the training distribution.
Why does this work? If the Platonic Representation Hypothesis is correct, then the universal structure isn’t tied to any particular domain but is a property of language itself (or more generally, of the data modality). Medical texts and Wikipedia articles may discuss different topics, but they use the same semantic relationships (hierarchies, analogies, contrasts, and associations) that follow the same geometric patterns regardless of domain. The translation captures this invariant structure, learning the transformation that aligns coordinate systems while preserving the universal geometry underneath rather than memorizing domain-specific content.
What Does This Mean?
Let’s step back and consider what these results imply. The Strong Platonic Representation Hypothesis, if validated more broadly, suggests that the space of possible learned representations is far more constrained than we thought. Different models are not exploring a vast landscape of alternative ways to represent meaning but converging to a narrow region, a canonical structure dictated by the statistical properties of language and the world it describes.
The Beautiful Side
This has both beautiful and troubling consequences. On the beautiful side, it means representation learning is discovering something real: word embeddings are not arbitrary constructs but reflect the intrinsic geometry of semantic relationships. When multiple models trained independently learn similar structures, it suggests those structures are inevitable features of meaning itself, not artifacts of a particular algorithm.
The Philosophical Question
It also raises deeper questions about what machine learning is doing. Are we building models that impose structure on data, or are we building telescopes that reveal pre-existing structure? If all sufficiently powerful models converge to the same representation, does that mean the representation was “already there” in some Platonic sense, waiting to be discovered?
Further Reading
Jha, R., Zhang, C., Shmatikov, V., & Morris, J. X. (2024). Harnessing the Universal Geometry of Embeddings. Project page
Huh, M., Cheung, B., Wang, T., & Isola, P. (2024). The Platonic Representation Hypothesis. arXiv:2405.07987
Mikolov, T., Yih, W., & Zweig, G. (2013). Linguistic Regularities in Continuous Space Word Representations. NAACL-HLT.